The Python Book
All — By Topic
2019 2016 2015 2014
Topics:
angle
argsort
beautifulsoup
binary
bisect
clean
collinear
covariance
cut_paste_cli
datafaking
dataframe
datetime
day_of_week
delta_time
df2sql
doctest
exif
floodfill
fold
format
frequency
gaussian
geocode
httpserver
is
join
legend
linalg
links
matrix
max
namedtuple
null
numpy
oo
osm
packaging
pandas
plot
point
range
regex
repeat
reverse
sample_words
shortcut
shorties
sort
stemming
strip_html
stripaccent
tools
visualization
zen
zip
angle
argsort
beautifulsoup
binary
bisect
clean
collinear
covariance
cut_paste_cli
datafaking
dataframe
datetime
day_of_week
delta_time
df2sql
doctest
exif
floodfill
fold
format
frequency
gaussian
geocode
httpserver
is
join
legend
linalg
links
matrix
max
namedtuple
null
numpy
oo
osm
packaging
pandas
plot
point
range
regex
repeat
reverse
sample_words
shortcut
shorties
sort
stemming
strip_html
stripaccent
tools
visualization
zen
zip
Tags:
3d aggregation angle archive argsort atan beautifulsoup binary bisect class clean collinear colsum comprehension count covariance csv cut_paste_cli datafaking dataframe datetime day_of_week delta_time deltatime df2sql distance doctest dotproduct dropnull exif file floodfill fold format formula frequency function garmin gaussian geocode geojson gps groupby html httpserver insert ipython is join kfold legend linalg links magic matrix max min namedtuple none null numpy onehot oo osm outer_product packaging pandas plot point quickies range read_data regex repeat reverse sample sample_data sample_words shortcut shorties sort split sqlite stack stemming string strip_html stripaccent tools track tuple visualization zen zip zipfile
3d aggregation angle archive argsort atan beautifulsoup binary bisect class clean collinear colsum comprehension count covariance csv cut_paste_cli datafaking dataframe datetime day_of_week delta_time deltatime df2sql distance doctest dotproduct dropnull exif file floodfill fold format formula frequency function garmin gaussian geocode geojson gps groupby html httpserver insert ipython is join kfold legend linalg links magic matrix max min namedtuple none null numpy onehot oo osm outer_product packaging pandas plot point quickies range read_data regex repeat reverse sample sample_data sample_words shortcut shorties sort split sqlite stack stemming string strip_html stripaccent tools track tuple visualization zen zip zipfile
format
20190731
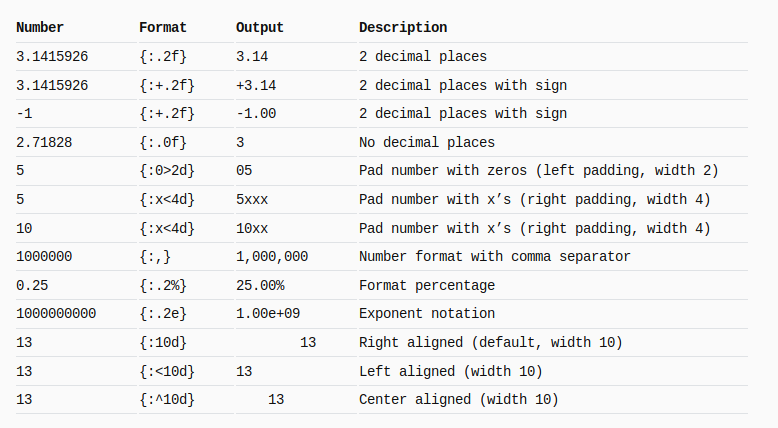
Python string format
Following snap is taken from here: mkaz.blog/code/python-string-format-cookbook. Go there, there are more examples
pandas
20190714
Convert a Garmin .FIT file and plot the heartrate of your run
Use gpsbabel to turn your FIT file into CSV:
gpsbabel -t -i garmin_fit -f 97D54119.FIT -o unicsv -F 97D54119.csvPandas imports:
import pandas as pd
import math
import matplotlib.pyplot as plt
pd.options.display.width=150Read the CSV file:
df=pd.read_csv('97D54119.csv',sep=',',skip_blank_lines=False)Show some points:
df.head(500).tail(10)
No Latitude Longitude Altitude Speed Heartrate Cadence Date Time
490 491 50.855181 4.826737 78.2 2.79 144 78.0 2019/07/13 06:44:22
491 492 50.855136 4.826739 77.6 2.79 147 78.0 2019/07/13 06:44:24
492 493 50.854962 4.826829 76.2 2.77 148 77.0 2019/07/13 06:44:32
493 494 50.854778 4.826951 77.4 2.77 146 78.0 2019/07/13 06:44:41
494 495 50.854631 4.827062 78.0 2.71 143 78.0 2019/07/13 06:44:49
495 496 50.854531 4.827174 79.2 2.70 146 77.0 2019/07/13 06:44:54
496 497 50.854472 4.827249 79.2 2.73 149 77.0 2019/07/13 06:44:57
497 498 50.854315 4.827418 79.8 2.74 149 76.0 2019/07/13 06:45:05
498 499 50.854146 4.827516 77.4 2.67 147 76.0 2019/07/13 06:45:14
499 500 50.853985 4.827430 79.0 2.59 144 75.0 2019/07/13 06:45:22Function to compute the distance (approximately) :
# function to approximately calculate the distance between 2 points
# from: http://www.movable-type.co.uk/scripts/latlong.html
def rough_distance(lat1, lon1, lat2, lon2):
lat1 = lat1 * math.pi / 180.0
lon1 = lon1 * math.pi / 180.0
lat2 = lat2 * math.pi / 180.0
lon2 = lon2 * math.pi / 180.0
r = 6371.0 #// km
x = (lon2 - lon1) * math.cos((lat1+lat2)/2)
y = (lat2 - lat1)
d = math.sqrt(x*x+y*y) * r
return dCompute the distance:
ds=[]
(d,priorlat,priorlon)=(0.0, 0.0, 0.0)
for t in df[['Latitude','Longitude']].itertuples():
if len(ds)>0:
d+=rough_distance(t.Latitude,t.Longitude, priorlat, priorlon)
ds.append(d)
(priorlat,priorlon)=(t.Latitude,t.Longitude)
df['CumulativeDist']=ds Let's plot!
df.plot(kind='line',x='CumulativeDist',y='Heartrate',color='red')
plt.show() 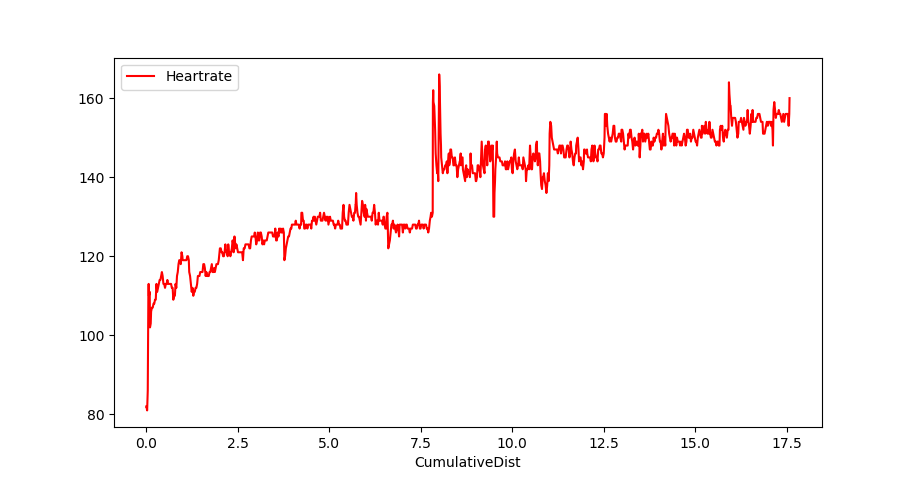
Or multiple columns:
plt.plot( df.CumulativeDist, df.Heartrate, color='red')
plt.plot( df.CumulativeDist, df.Altitude, color='blue')
plt.show()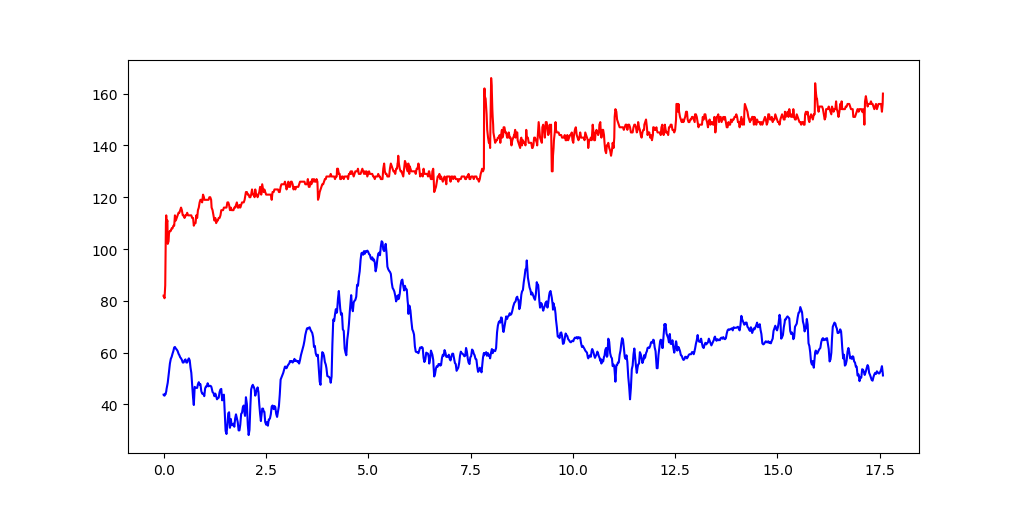
dataframe
20190202
Turn a dataframe into an array
eg. dataframe cn
cn
asciiname population elevation
128677 Crossett 5507 58
7990 Santa Maria da Vitoria 23488 438
25484 Shanling 0 628
95882 Colonia Santa Teresa 36845 2286
38943 Blomberg 1498 4
7409 Missao Velha 13106 364
36937 Goerzig 1295 81Turn into an arrary
cn.iloc[range(len(cn))].values
array([['Yuhu', 0, 15],
['Traventhal', 551, 42],
['Velabisht', 0, 60],
['Almorox', 2319, 539],
['Abuyog', 15632, 6],
['Zhangshan', 0, 132],
['Llica de Vall', 0, 136],
['Capellania', 2252, 31],
['Mezocsat', 6519, 91],
['Vars', 1634, 52]], dtype=object)Sidenote: cn was pulled from city data: cn=df.sample(7)[['asciiname','population','elevation']].
dataframe
20190202
Filter a dataframe to retain rows with non-null values
Eg. you want only the data where the 'population' column has non-null values.
In short
df=df[df['population'].notnull()]Alternative, replace the null value with something:
df['population']=df['population'].fillna(0) In detail
import numpy as np
import pandas as pd
# setup the dataframe
data=[[ 'Isle of Skye', 9232, 124 ],
[ 'Vieux-Charmont', np.nan, 320 ],
[ 'Indian Head', 3844, 35 ],
[ 'Cihua', np.nan, 178 ],
[ 'Miasteczko Slaskie', 7327, 301 ],
[ 'Wawa', np.nan, 7 ],
[ 'Bat Khela', 46079, 673 ]]
df=pd.DataFrame(data, columns=['asciiname','population','elevation'])
#display the dataframe
df
asciiname population elevation
0 Isle of Skye 9232.0 124
1 Vieux-Charmont NaN 320
2 Indian Head 3844.0 35
3 Cihua NaN 178
4 Miasteczko Slaskie 7327.0 301
5 Wawa NaN 7
# retain only the rows where population has a non-null value
df=df[df['population'].notnull()]
asciiname population elevation
0 Isle of Skye 9232.0 124
2 Indian Head 3844.0 35
4 Miasteczko Slaskie 7327.0 301
6 Bat Khela 46079.0 673