The Python Book
All — By Topic
2019 2016 2015 2014
angle
argsort
beautifulsoup
binary
bisect
clean
collinear
covariance
cut_paste_cli
datafaking
dataframe
datetime
day_of_week
delta_time
df2sql
doctest
exif
floodfill
fold
format
frequency
gaussian
geocode
httpserver
is
join
legend
linalg
links
matrix
max
namedtuple
null
numpy
oo
osm
packaging
pandas
plot
point
range
regex
repeat
reverse
sample_words
shortcut
shorties
sort
stemming
strip_html
stripaccent
tools
visualization
zen
zip
3d aggregation angle archive argsort atan beautifulsoup binary bisect class clean collinear colsum comprehension count covariance csv cut_paste_cli datafaking dataframe datetime day_of_week delta_time deltatime df2sql distance doctest dotproduct dropnull exif file floodfill fold format formula frequency function garmin gaussian geocode geojson gps groupby html httpserver insert ipython is join kfold legend linalg links magic matrix max min namedtuple none null numpy onehot oo osm outer_product packaging pandas plot point quickies range read_data regex repeat reverse sample sample_data sample_words shortcut shorties sort split sqlite stack stemming string strip_html stripaccent tools track tuple visualization zen zip zipfile
List EXIF details of a photo
This program walks a directory, and lists selected exif data.
Install module exifread first.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
The topics of the kubercon (Kubernetes conference)
Input
Markdown doc 'source.md' with all the presentation titles plus links:
[2000 Nodes and Beyond: How We Scaled Kubernetes to 60,000-Container Clusters
and Where We're Going Next - Marek Grabowski, Google Willow
A](/event/8K8w/2000-nodes-and-beyond-how-we-scaled-kubernetes-to-60000
-container-clusters-and-where-were-going-next-marek-grabowski-google) [How Box
Runs Containers in Production with Kubernetes - Sam Ghods, Box Grand Ballroom
D](/event/8K8u/how-box-runs-containers-in-production-with-kubernetes-sam-
ghods-box) [ITNW (If This Now What) - Orchestrating an Enterprise - Michael
Ward, Pearson Grand Ballroom C](/event/8K8t/itnw-if-this-now-what-
orchestrating-an-enterprise-michael-ward-pearson) [Unik: Unikernel Runtime for
Kubernetes - Idit Levine, EMC Redwood AB](/event/8K8v/unik-unikernel-runtime-
..
..Step 1: generate download script
Grab the links from 'source.md' and download them.
#!/usr/bin/python
# -*- coding: utf-8 -*-
import re
buf=""
infile = file('source.md', 'r')
for line in infile.readlines():
buf+=line.rstrip('\n')
oo=1
while True:
match = re.search( '^(.*?\()(/.[^\)]*)(\).*$)', buf)
if match is None:
break
url="https://cnkc16.sched.org"+match.group(2)
print "wget '{}' -O {:0>4d}.html".format(url,oo)
oo+=1
buf=match.group(3)Step 2: download the html
Execute the script generated by above code, and put the resulting files in directory 'content' :
wget 'https://cnkc16.sched.org/event/8K8w/2000-nodes-and-beyond-how-
we-scaled-kubernetes-to-60000-container-clusters-and-where-were-
going-next-marek-grabowski-google' -O 0001.html
wget 'https://cnkc16.sched.org/event/8K8u/how-box-runs-containers-in-
production-with-kubernetes-sam-ghods-box' -O 0002.html
wget 'https://cnkc16.sched.org/event/8K8t/itnw-if-this-now-what-
orchestrating-an-enterprise-michael-ward-pearson' -O 0003.html
.. Step 3: parse with beautiful soup
#!/usr/bin/python
# -*- coding: utf-8 -*-
from BeautifulSoup import *
import os
import re
import codecs
#outfile = file('text.md', 'w')
# ^^^ --> UnicodeEncodeError:
# 'ascii' codec can't encode character u'\u2019'
# in position 73: ordinal not in range(128)
outfile= codecs.open("text.md", "w", "utf-8")
file_ls=[]
for filename in os.listdir("content"):
if filename.endswith(".html"):
file_ls.append(filename)
for filename in sorted(file_ls):
infile = file('content/'+filename,'r')
content = infile.read()
infile.close()
soup = BeautifulSoup(content.decode('utf-8','ignore'))
div= soup.find('div', attrs={'class':'sched-container-inner'})
el_ls= div.findAll('span')
el=el_ls[0].text.strip()
title=re.sub(' - .*$','',el)
speaker=re.sub('^.* - ','',el)
outfile.write( u'\n\n## {}\n'.format(title))
outfile.write( u'\n\n{}\n'.format(speaker) )
det= div.find('div', attrs={'class':'tip-description'})
if det is not None:
outfile.write( u'\n{}\n'.format(det.text.strip() ) )Incrementally update geocoded data
Startpoint: we have a sqlite3 database with (dirty) citynames and country codes. We would like to have the lat/lon coordinates, for each place.
Here some sample data, scraped from the Brussels marathon-results webpage, indicating the town of residence and nationality of the athlete:
LA CELLE SAINT CLOUD, FRA
TERTRE, BEL
FREDERICIA, DNK But sometimes the town and country don't match up, eg:
HEVERLEE CHN
WOLUWE-SAINT-PIERRE JPN
BUIZINGEN FRA For the geocoding we make use of nominatim.openstreetmap.org. The 3-letter country code also needs to be translated into a country name, for which we use the file /u01/data/20150215_country_code_iso/country_codes.txt.
The places for which we don't get valid (lat,lon) coordinates we put (0,0).
We run this script multiple times, small batches in the beginning, to be able see what the exceptions occur, and bigger batches in the end (when problems have been solved).
In between runs the data may be manually modified by opening the sqlite3 database, and updating/deleting the t_geocode table.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | |
A few queries
Total number of places:
select count(1) from t_geocode
916Number of places for which we didn't find valid coordinates :
select count(1) from t_geocode where lat=0 and lon=0
185Turn a pandas dataframe into a dictionary
eg. create a mapping of a 3 digit code to a country name
BEL -> Belgium
CHN -> China
FRA -> France
..Code:
df=pd.io.parsers.read_table(
'/u01/data/20150215_country_code_iso/country_codes.txt',
sep='|')
c3d=df.set_index('c3')['country'].to_dict()Result:
c3d['AUS']
'Australia'
c3d['GBR']
'United Kingdom'Create a DB by scraping a webpage
Download all the webpages and put them in a zipfile (to avoid 're-downloading' on each try).
If you want to work 'direct', then use this to read the html content of a url:
html_doc=urllib.urlopen(url).read()Preparation: create database table
cur.execute('DROP TABLE IF EXISTS t_result')
cur.execute('''
CREATE TABLE t_result(
pos varchar(128),
nr varchar(128),
gesl varchar(128),
naam varchar(128),
leeftijd varchar(128),
ioc varchar(128),
tijd varchar(128),
tkm varchar(128),
gem varchar(128),
cat_plaats varchar(128),
cat_naam varchar(128),
gemeente varchar(128)
)
''') ## Pull each html file from the zipfile
zf=zipfile.ZipFile('brx_marathon_html.zip','r')
for fn in zf.namelist():
try:
content= zf.read(fn)
handle_content(content)
except KeyError:
print 'ERROR: %s not in zip file' % fn
breakParse the content of each html file with Beautiful Soup
soup = BeautifulSoup(content)
table= soup.find('table', attrs={'cellspacing':'0', 'cellpadding':'2'})
rows = table.findAll('tr')
for row in rows:
cols = row.findAll('td')
e = [ ele.text.strip() for ele in cols]
if len(e)>10:
cur.execute('INSERT INTO T_RESULT VALUES ( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?,? )',
(e[0],e[1],e[2],e[3],e[4],e[5],e[6],e[7],e[8],e[9],e[10],e[11]) )Note: the above code is beautiful soup 3, for beautiful soup 4, the findAll needs to be replaced by find_all.
Complete source code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | |
Days between dates
Q: how many days are there in between these days ?
'29 sep 2016', '7 jul 2016', '28 apr 2016', '10 mar 2016', '14 jan 2016'Solution:
from datetime import datetime,timedelta
a=map(lambda x: datetime.strptime(x,'%d %b %Y'),
['29 sep 2016', '7 jul 2016', '28 apr 2016', '10 mar 2016', '14 jan 2016'] )
def dr(ar):
if len(ar)>1:
print "{:%d %b %Y} .. {} .. {:%d %b %Y} ".format(
ar[0], (ar[0]-ar[1]).days, ar[1])
dr(ar[1:]) Output:
dr(a)
29 Sep 2016 .. 84 .. 07 Jul 2016
07 Jul 2016 .. 70 .. 28 Apr 2016
28 Apr 2016 .. 49 .. 10 Mar 2016
10 Mar 2016 .. 56 .. 14 Jan 2016 Simple OO program
Also from Dr. Chuck.
class PartyAnimal:
x = 0
def party(self) :
self.x = self.x + 1
print "So far",self.x
an = PartyAnimal()
an.party()
an.party()
an.party()Class with constructor / destructor
class PartyAnimal:
x = 0
def __init__(self):
print "I am constructed"
def party(self) :
self.x = self.x + 1
print "So far",self.x
def __del__(self):
print "I am destructed", self.x
an = PartyAnimal()
an.party()
an.party()
an.party()Field name added to Class
class PartyAnimal:
x = 0
name = ""
def __init__(self, nam):
self.name = nam
print self.name,"constructed"
def party(self) :
self.x = self.x + 1
print self.name,"party count",self.x
s = PartyAnimal("Sally")
s.party()
j = PartyAnimal("Jim")
j.party()
s.party()Inheritance
class PartyAnimal:
x = 0
name = ""
def __init__(self, nam):
self.name = nam
print self.name,"constructed"
def party(self) :
self.x = self.x + 1
print self.name,"party count",self.x
class FootballFan(PartyAnimal):
points = 0
def touchdown(self):
self.points = self.points + 7
self.party()
print self.name,"points",self.points
s = PartyAnimal("Sally")
s.party()
j = FootballFan("Jim")
j.party()
j.touchdown()Here is Dr. Chuck's RegEx "cheat sheet". You can also download it here:
www.dr-chuck.net/pythonlearn/lectures/Py4Inf-11-Regex-Guide.doc

Here's Dr. Chucks book on learning python: www.pythonlearn.com/html-270
For more information about using regular expressions in Python, see docs.python.org/2/howto/regex.html
eg. read a csv file that has nasty quotes, and save it as tab-separated.
import pandas as pd
import csv
colnames= ["userid", "movieid", "tag", "timestamp"]
df=pd.io.parsers.read_table("tags.csv",
sep=",", header=0, names= colnames,
quoting=csv.QUOTE_ALL)Write:
df.to_csv('tags.tsv', index=False, sep='\t')Pie chart
Make a pie-chart of the top-10 number of cities per country in the file cities15000.txt
import pandas as pd
import matplotlib.pyplot as pltLoad city data, but only the country column.
colnames= [ "country" ]
df=pd.io.parsers.read_table("/usr/share/libtimezonemap/ui/cities15000.txt",
sep="\t", header=None, names= colnames,
usecols=[ 8 ])Get the counts:
cnts=df['country'].value_counts()
total_cities=cnts.sum()
22598Keep the top 10:
t10=cnts.order(ascending=False)[:10]
US 2900
IN 2398
BR 1195
DE 986
RU 951
CN 788
JP 752
IT 674
GB 625
FR 616What are the percentages ? (to display in the label)
pct=t10.map( lambda x: round((100.*x)/total_cities,2)).values
array([ 12.83, 10.61, 5.29, 4.36, 4.21, 3.49, 3.33, 2.98, 2.77, 2.73])Labels: country-name + percentage
labels=[ "{} ({}%)".format(cn,pc) for (cn,pc) in zip( t10.index.values, pct)]
['US (12.83%)', 'IN (10.61%)', 'BR (5.29%)', 'DE (4.36%)', 'RU (4.21%)', 'CN (3.49%)',
'JP (3.33%)', 'IT (2.98%)', 'GB (2.77%)', 'FR (2.73%)']Values:
values=t10.values
array([2900, 2398, 1195, 986, 951, 788, 752, 674, 625, 616])Plot
plt.style.use('ggplot')
plt.title('Number of Cities per Country\nIn file cities15000.txt')
plt.pie(values,labels=labels)
plt.show()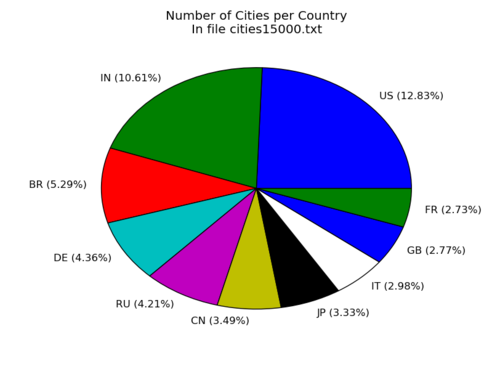
Interesting blog post.
OpenStreetMap city blocks as GeoJSON polygons
Extracting blocks within a city as GeoJSON polygons from OpenStreetMap data
I'll talk about using QGIS software to explore and visualize LARGE maps and provide a Python script (you don't need QGIS for this) for converting lines that represent streets to polygons that represent city blocks. The script will use the polygonize function from Shapely but you need to preprocess the OSM data first which is the secret sauce.
peteris.rocks/blog/openstreetmap-city-blocks-as-geojson-polygons
Summary:
- Download GeoJSON files from Mapzen Metro Extracts
- Filter lines with filter.py
- Split LineStrings with multiple points to LineStrings with two points with split-lines.py
- Create polygons with polygonize.py
- Look at results with QGIS or geojson.io
GeoJSON: geojson.io/#map=14/-14.4439/28.4334
Plot a couple of Gaussians
import numpy as np
from math import pi
from math import sqrt
import matplotlib.pyplot as plt
def gaussian(x, mu, sig):
return 1./(sqrt(2.*pi)*sig)*np.exp(-np.power((x - mu)/sig, 2.)/2)
xv= map(lambda x: x/10.0, range(0,120,1))
mu= [ 2.0, 7.0, 9.0 ]
sig=[ 0.45, 0.70, 0.3 ]
for g in range(len(mu)):
m=mu[g]
s=sig[g]
yv=map( lambda x: gaussian(x,m,s), xv )
plt.plot(xv,yv)
plt.show()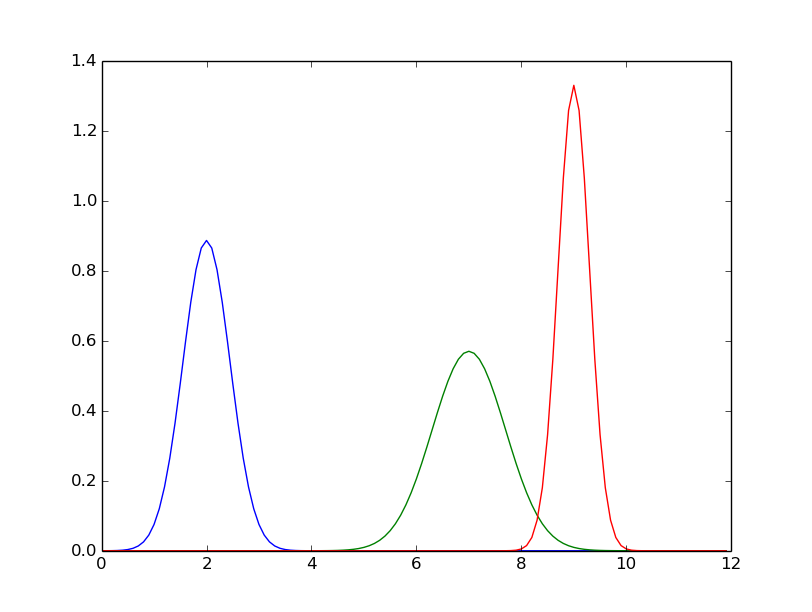
np.random.multivariate_normal()
import numpy as np
import matplotlib.pyplot as plt
means = [
[9, 9], # top right
[1, 9], # top left
[1, 1], # bottom left
[9, 1], # bottom right
]
covariances = [
[ [.5, 0.], # covariance top right
[0, .5] ],
[[.1, .0], # covariance top left
[.0, .9]],
[[.9, 0.], # covariance bottom left
[0, .1]],
[[0.5, 0.5], # covariance bottom right
[0.5, 0.5]] ]
data = []
for k in range(len(means)):
for i in range(100) :
x = np.random.multivariate_normal(means[k], covariances[k])
data.append(x)
d=np.vstack(data)
plt.plot(d[:,0], d[:,1],'ko')
plt.show()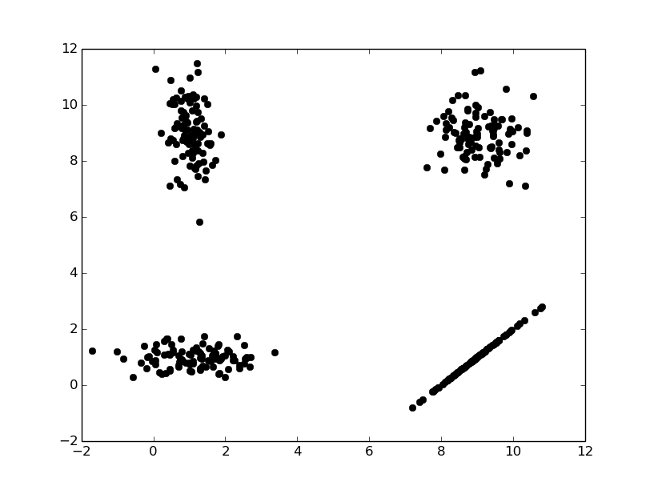
Strip accents from letters
See how sklearn does it, functions:
strip_accents_ascii(s)
strip_accents_unicode(s)github.com/scikit-learn/scikit-learn/blob/master/sklearn/feature_extraction/text.py
See also: stackoverflow.com/questions/517923/what-is-the-best-way-to-remove-accents-in-a-python-unicode-string
Binary vector
You have this vector that is a representation of a binary number. How to calculate the decimal value? Make the dot-product with the powers of two vector!
eg.
xbin=[1,1,1,1,1,0,1,0,0,0,0,0,0,0,0,0]
xdec=?Introduction:
import numpy as np
powers_of_two = (1 << np.arange(15, -1, -1))
array([32768, 16384, 8192, 4096, 2048, 1024, 512, 256, 128,
64, 32, 16, 8, 4, 2, 1])
seven=np.array( [0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1] )
seven.dot(powers_of_two)
7
thirtytwo=np.array( [0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0] )
thirtytwo.dot(powers_of_two)
32Solution:
xbin=np.array([1,1,1,1,1,0,1,0,0,0,0,0,0,0,0,0])
xdec=xbin.dot(powers_of_two)
=64000You can also write the binary vector with T/F:
xbin=np.array([True,True,True,True,True,False,True,False,
False,False,False,False,False,False,False,False])
xdec=xbin.dot(powers_of_two)
=64000Regex: positive lookbehind assertion
(?<=...) Matches if the current position in the string is preceded by a match for ... that ends at the current position.
eg.
s="Yes, taters is a synonym for potaters or potatoes."
re.sub('(?<=po)taters','TATERS', s)
'Yes, taters is a synonym for poTATERS or potatoes.'Or example from python doc:
m = re.search('(?<=abc)def', 'abcdef')
m.group(0)
'def'Sample with replacement
Create a vector composed of randomly selected elements of a smaller vector. Ie. sample with replacement.
import numpy as np
src_v=np.array([1,2,3,5,8,13,21])
trg_v= src_v[np.random.randint( len(src_v), size=30)]
array([ 3, 8, 21, 5, 3, 3, 21, 5, 21, 3, 2, 13, 3, 21, 2, 2, 13,
5, 3, 21, 1, 2, 13, 3, 5, 3, 8, 8, 3, 1])Dataframe aggregation fun
Load the city dataframe into dataframe df.
Summary statistic of 1 column
df.population.describe()
count 2.261100e+04
mean 1.113210e+05
std 4.337739e+05
min 0.000000e+00
25% 2.189950e+04
50% 3.545000e+04
75% 7.402450e+04
max 1.460851e+07Summary statistic per group
Load the city dataframe into df, then:
t1=df[['country','population']].groupby(['country'])
t2=t1.agg( ['min','mean','max','count'])
t2.sort_values(by=[ ('population','count') ],ascending=False).head(20)Output:
population
min mean max count
country
US 15002 62943.294138 8175133 2900
IN 15007 109181.708924 12691836 2398
BR 0 104364.320502 10021295 1195
DE 0 57970.979716 3426354 986
RU 15048 101571.065195 10381222 951
CN 15183 357967.030457 14608512 788
JP 15584 136453.906915 8336599 752
IT 895 49887.442136 2563241 674
GB 15024 81065.611200 7556900 625
FR 15009 44418.920455 2138551 616
ES 15006 65588.432282 3255944 539
MX 15074 153156.632735 12294193 501
PH 15066 100750.534884 10444527 430
TR 15058 142080.305263 11174257 380
ID 17504 170359.848901 8540121 364
PL 15002 64935.379421 1702139 311
PK 15048 160409.378641 11624219 309
NL 15071 53064.727626 777725 257
UA 15012 103468.816000 2514227 250
NG 15087 205090.336207 9000000 232Note on selecting a multilevel column
Eg. select 'min' via tuple ('population','min').
t2[ t2[('population','min')]>50000 ]
population
min mean max count
country
BB 98511 9.851100e+04 98511 1
CW 125000 1.250000e+05 125000 1
HK 288728 3.107000e+06 7012738 3
MO 520400 5.204000e+05 520400 1
MR 72337 3.668685e+05 661400 2
MV 103693 1.036930e+05 103693 1
SB 56298 5.629800e+04 56298 1
SG 3547809 3.547809e+06 3547809 1
ST 53300 5.330000e+04 53300 1
TL 150000 1.500000e+05 150000 1Turn a dataframe into sql statements
The easiest way is to go via sqlite!
eg. the two dataframes udf and tdf.
import sqlite3
con=sqlite3.connect('txdb.sqlite')
udf.to_sql(name='t_user', con=con, index=False)
tdf.to_sql(name='t_transaction', con=con, index=False)
con.close()Then on the command line:
sqlite3 txdb.sqlite .dump > create.sql This is the created create.sql script:
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE "t_user" (
"uid" INTEGER,
"name" TEXT
);
INSERT INTO "t_user" VALUES(9000,'Gerd Abrahamsson');
INSERT INTO "t_user" VALUES(9001,'Hanna Andersson');
INSERT INTO "t_user" VALUES(9002,'August Bergsten');
INSERT INTO "t_user" VALUES(9003,'Arvid Bohlin');
INSERT INTO "t_user" VALUES(9004,'Edvard Marklund');
INSERT INTO "t_user" VALUES(9005,'Ragnhild Brännström');
INSERT INTO "t_user" VALUES(9006,'Börje Wallin');
INSERT INTO "t_user" VALUES(9007,'Otto Byström');
INSERT INTO "t_user" VALUES(9008,'Elise Dahlström');
CREATE TABLE "t_transaction" (
"xid" INTEGER,
"uid" INTEGER,
"amount" INTEGER,
"date" TEXT
);
INSERT INTO "t_transaction" VALUES(5000,9008,498,'2016-02-21 06:28:49');
INSERT INTO "t_transaction" VALUES(5001,9003,268,'2016-01-17 13:37:38');
INSERT INTO "t_transaction" VALUES(5002,9003,621,'2016-02-24 15:36:53');
INSERT INTO "t_transaction" VALUES(5003,9007,-401,'2016-01-14 16:43:27');
INSERT INTO "t_transaction" VALUES(5004,9004,720,'2016-05-14 16:29:54');
INSERT INTO "t_transaction" VALUES(5005,9007,-492,'2016-02-24 23:58:57');
INSERT INTO "t_transaction" VALUES(5006,9002,-153,'2016-02-18 17:58:33');
INSERT INTO "t_transaction" VALUES(5007,9008,272,'2016-05-26 12:00:00');
INSERT INTO "t_transaction" VALUES(5008,9005,-250,'2016-02-24 23:14:52');
INSERT INTO "t_transaction" VALUES(5009,9008,82,'2016-04-20 18:33:25');
INSERT INTO "t_transaction" VALUES(5010,9006,549,'2016-02-16 14:37:25');
INSERT INTO "t_transaction" VALUES(5011,9008,-571,'2016-02-28 13:05:33');
INSERT INTO "t_transaction" VALUES(5012,9008,814,'2016-03-20 13:29:11');
INSERT INTO "t_transaction" VALUES(5013,9005,-114,'2016-02-06 14:55:10');
INSERT INTO "t_transaction" VALUES(5014,9005,819,'2016-01-18 10:50:20');
INSERT INTO "t_transaction" VALUES(5015,9001,-404,'2016-02-20 22:08:23');
INSERT INTO "t_transaction" VALUES(5016,9000,-95,'2016-05-09 10:26:05');
INSERT INTO "t_transaction" VALUES(5017,9003,428,'2016-03-27 15:30:47');
INSERT INTO "t_transaction" VALUES(5018,9002,-549,'2016-04-15 21:44:49');
INSERT INTO "t_transaction" VALUES(5019,9001,-462,'2016-03-09 20:32:35');
INSERT INTO "t_transaction" VALUES(5020,9004,-339,'2016-05-03 17:11:21');
COMMIT;The script doesn't create the indexes (because of Index='False'), so here are the statements:
CREATE INDEX "ix_t_user_uid" ON "t_user" ("uid");
CREATE INDEX "ix_t_transaction_xid" ON "t_transaction" ("xid");Or better: create primary keys on those tables!
Join two dataframes, sql style
You have a number of users, and a number of transactions against those users. Join these 2 dataframes.
import pandas as pd User dataframe
ids= [9000, 9001, 9002, 9003, 9004, 9005, 9006, 9007, 9008]
nms=[u'Gerd Abrahamsson', u'Hanna Andersson', u'August Bergsten',
u'Arvid Bohlin', u'Edvard Marklund', u'Ragnhild Br\xe4nnstr\xf6m',
u'B\xf6rje Wallin', u'Otto Bystr\xf6m',u'Elise Dahlstr\xf6m']
udf=pd.DataFrame(ids, columns=['uid'])
udf['name']=nmsContent of udf:
uid name
0 9000 Gerd Abrahamsson
1 9001 Hanna Andersson
2 9002 August Bergsten
3 9003 Arvid Bohlin
4 9004 Edvard Marklund
5 9005 Ragnhild Brännström
6 9006 Börje Wallin
7 9007 Otto Byström
8 9008 Elise DahlströmTransaction dataframe
tids= [5000, 5001, 5002, 5003, 5004, 5005, 5006, 5007, 5008, 5009, 5010, 5011, 5012,
5013, 5014, 5015, 5016, 5017, 5018, 5019, 5020]
uids= [9008, 9003, 9003, 9007, 9004, 9007, 9002, 9008, 9005, 9008, 9006, 9008, 9008,
9005, 9005, 9001, 9000, 9003, 9002, 9001, 9004]
tamt= [498, 268, 621, -401, 720, -492, -153, 272, -250, 82, 549, -571, 814, -114,
819, -404, -95, 428, -549, -462, -339]
tdt= ['2016-02-21 06:28:49', '2016-01-17 13:37:38', '2016-02-24 15:36:53',
'2016-01-14 16:43:27', '2016-05-14 16:29:54', '2016-02-24 23:58:57',
'2016-02-18 17:58:33', '2016-05-26 12:00:00', '2016-02-24 23:14:52',
'2016-04-20 18:33:25', '2016-02-16 14:37:25', '2016-02-28 13:05:33',
'2016-03-20 13:29:11', '2016-02-06 14:55:10', '2016-01-18 10:50:20',
'2016-02-20 22:08:23', '2016-05-09 10:26:05', '2016-03-27 15:30:47',
'2016-04-15 21:44:49', '2016-03-09 20:32:35', '2016-05-03 17:11:21']
tdf=pd.DataFrame(tids, columns=['xid'])
tdf['uid']=uids
tdf['amount']=tamt
tdf['date']=tdtContent of tdf:
xid uid amount date
0 5000 9008 498 2016-02-21 06:28:49
1 5001 9003 268 2016-01-17 13:37:38
2 5002 9003 621 2016-02-24 15:36:53
3 5003 9007 -401 2016-01-14 16:43:27
4 5004 9004 720 2016-05-14 16:29:54
5 5005 9007 -492 2016-02-24 23:58:57
6 5006 9002 -153 2016-02-18 17:58:33
7 5007 9008 272 2016-05-26 12:00:00
8 5008 9005 -250 2016-02-24 23:14:52
9 5009 9008 82 2016-04-20 18:33:25
10 5010 9006 549 2016-02-16 14:37:25
11 5011 9008 -571 2016-02-28 13:05:33
12 5012 9008 814 2016-03-20 13:29:11
13 5013 9005 -114 2016-02-06 14:55:10
14 5014 9005 819 2016-01-18 10:50:20
15 5015 9001 -404 2016-02-20 22:08:23
16 5016 9000 -95 2016-05-09 10:26:05
17 5017 9003 428 2016-03-27 15:30:47
18 5018 9002 -549 2016-04-15 21:44:49
19 5019 9001 -462 2016-03-09 20:32:35
20 5020 9004 -339 2016-05-03 17:11:21Join sql-style: pd.merge
pd.merge( tdf, udf, how='inner', left_on='uid', right_on='uid')
xid uid amount date name
0 5000 9008 498 2016-02-21 06:28:49 Elise Dahlström
1 5007 9008 272 2016-05-26 12:00:00 Elise Dahlström
2 5009 9008 82 2016-04-20 18:33:25 Elise Dahlström
3 5011 9008 -571 2016-02-28 13:05:33 Elise Dahlström
4 5012 9008 814 2016-03-20 13:29:11 Elise Dahlström
5 5001 9003 268 2016-01-17 13:37:38 Arvid Bohlin
6 5002 9003 621 2016-02-24 15:36:53 Arvid Bohlin
7 5017 9003 428 2016-03-27 15:30:47 Arvid Bohlin
8 5003 9007 -401 2016-01-14 16:43:27 Otto Byström
9 5005 9007 -492 2016-02-24 23:58:57 Otto Byström
10 5004 9004 720 2016-05-14 16:29:54 Edvard Marklund
11 5020 9004 -339 2016-05-03 17:11:21 Edvard Marklund
12 5006 9002 -153 2016-02-18 17:58:33 August Bergsten
13 5018 9002 -549 2016-04-15 21:44:49 August Bergsten
14 5008 9005 -250 2016-02-24 23:14:52 Ragnhild Brännström
15 5013 9005 -114 2016-02-06 14:55:10 Ragnhild Brännström
16 5014 9005 819 2016-01-18 10:50:20 Ragnhild Brännström
17 5010 9006 549 2016-02-16 14:37:25 Börje Wallin
18 5015 9001 -404 2016-02-20 22:08:23 Hanna Andersson
19 5019 9001 -462 2016-03-09 20:32:35 Hanna Andersson
20 5016 9000 -95 2016-05-09 10:26:05 Gerd AbrahamssonSidenote: fake data creation
This is the way the above fake data was created:
import random
from faker import Factory
fake = Factory.create('sv_SE')
ids=[]
nms=[]
for i in range(0,9):
ids.append(9000+i)
nms.append(fake.name())
print "%d\t%s" % ( ids[i],nms[i])
tids=[]
uids=[]
tamt=[]
tdt=[]
sign=[-1,1]
for i in range(0,21):
tids.append(5000+i)
tamt.append(sign[random.randint(0,1)]*random.randint(80,900))
uids.append(ids[random.randint(0,len(ids)-1)])
tdt.append(str(fake.date_time_this_year()))
print "%d\t%d\t%d\t%s" % ( tids[i], tamt[i], uids[i], tdt[i])Anonymizing Data
Read this article on faker:
blog.districtdatalabs.com/a-practical-guide-to-anonymizing-datasets-with-python-faker
The goal: given a target dataset (for example, a CSV file with multiple columns), produce a new dataset such that for each row in the target, the anonymized dataset does not contain any personally identifying information. The anonymized dataset should have the same amount of data and maintain its analytical value. As shown in the figure below, one possible transformation simply maps original information to fake and therefore anonymous information but maintains the same overall structure.
Read data from a zipfile into a dataframe
import pandas as pd
import zipfile
z = zipfile.ZipFile("lending-club-data.csv.zip")
df=pd.io.parsers.read_table(z.open("lending-club-data.csv"), sep=",")
z.close()Calculate the cumulative distance of gps trackpoints
Prep:
import pandas as pd
import mathFunction to calculate the distance:
# function to approximately calculate the distance between 2 points
# from: http://www.movable-type.co.uk/scripts/latlong.html
def rough_distance(lat1, lon1, lat2, lon2):
lat1 = lat1 * math.pi / 180.0
lon1 = lon1 * math.pi / 180.0
lat2 = lat2 * math.pi / 180.0
lon2 = lon2 * math.pi / 180.0
r = 6371.0 #// km
x = (lon2 - lon1) * math.cos((lat1+lat2)/2)
y = (lat2 - lat1)
d = math.sqrt(x*x+y*y) * r
return dRead data:
df=pd.io.parsers.read_table("trk.tsv",sep="\t")
# drop some columns (for clarity)
df=df.drop(['track','ele','tm_str'],axis=1) Sample:
df.head()
lat lon
0 50.848408 4.787456
1 50.848476 4.787367
2 50.848572 4.787275
3 50.848675 4.787207
4 50.848728 4.787189The prior-latitude column is the latitude column shifted by 1 unit:
df['prior_lat']= df['lat'].shift(1)
prior_lat_ix=df.columns.get_loc('prior_lat')
df.iloc[0,prior_lat_ix]= df.lat.iloc[0]The prior-longitude column is the longitude column shifted by 1 unit:
df['prior_lon']= df['lon'].shift(1)
prior_lon_ix=df.columns.get_loc('prior_lon')
df.iloc[0,prior_lon_ix]= df.lon.iloc[0]Calculate the distance:
df['dist']= df[ ['lat','lon','prior_lat','prior_lon'] ].apply(
lambda r : rough_distance ( r[0], r[1], r[2], r[3]) , axis=1)Calculate the cumulative distance
cum=0
cum_dist=[]
for d in df['dist']:
cum=cum+d
cum_dist.append(cum)
df['cum_dist']=cum_distSample:
df.head()
lat lon prior_lat prior_lon dist cum_dist
0 50.848408 4.787456 50.848408 4.787456 0.000000 0.000000
1 50.848476 4.787367 50.848408 4.787456 0.009831 0.009831
2 50.848572 4.787275 50.848476 4.787367 0.012435 0.022266
3 50.848675 4.787207 50.848572 4.787275 0.012399 0.034665
4 50.848728 4.787189 50.848675 4.787207 0.006067 0.040732
df.tail()
lat lon prior_lat prior_lon dist cum_dist
1012 50.847164 4.788163 50.846962 4.788238 0.023086 14.937470
1013 50.847267 4.788134 50.847164 4.788163 0.011634 14.949104
1014 50.847446 4.788057 50.847267 4.788134 0.020652 14.969756
1015 50.847630 4.787978 50.847446 4.788057 0.021097 14.990853
1016 50.847729 4.787932 50.847630 4.787978 0.011496 15.002349Onehot encode the categorical data of a data-frame
.. using the pandas get_dummies function.
Data:
import StringIO
import pandas as pd
data_strio=StringIO.StringIO('''category reason species
Decline Genuine 24
Improved Genuine 16
Improved Misclassified 85
Decline Misclassified 41
Decline Taxonomic 2
Improved Taxonomic 7
Decline Unclear 41
Improved Unclear 117''')
df=pd.read_fwf(data_strio)One hot encode 'category':
cat_oh= pd.get_dummies(df['category'])
cat_oh.columns= map( lambda x: "cat__"+x.lower(), cat_oh.columns.values)
cat_oh
cat__decline cat__improved
0 1 0
1 0 1
2 0 1
3 1 0
4 1 0
5 0 1
6 1 0
7 0 1Do the same for 'reason' :
reason_oh= pd.get_dummies(df['reason'])
reason_oh.columns= map( lambda x: "rsn__"+x.lower(), reason_oh.columns.values)Combine
Combine the columns into a new dataframe:
ohdf= pd.concat( [ cat_oh, reason_oh, df['species']], axis=1)Result:
ohdf
cat__decline cat__improved rsn__genuine rsn__misclassified \
0 1 0 1 0
1 0 1 1 0
2 0 1 0 1
3 1 0 0 1
4 1 0 0 0
5 0 1 0 0
6 1 0 0 0
7 0 1 0 0
rsn__taxonomic rsn__unclear species
0 0 0 24
1 0 0 16
2 0 0 85
3 0 0 41
4 1 0 2
5 1 0 7
6 0 1 41
7 0 1 117 Or if the 'drop' syntax on the dataframe is more convenient to you:
ohdf= pd.concat( [ cat_oh, reason_oh,
df.drop(['category','reason'], axis=1) ],
axis=1)Read a fixed-width datafile inline
import StringIO
import pandas as pd
data_strio=StringIO.StringIO('''category reason species
Decline Genuine 24
Improved Genuine 16
Improved Misclassified 85
Decline Misclassified 41
Decline Taxonomic 2
Improved Taxonomic 7
Decline Unclear 41
Improved Unclear 117''')Turn the string_IO into a dataframe:
df=pd.read_fwf(data_strio)Check the content:
df
category reason species
0 Decline Genuine 24
1 Improved Genuine 16
2 Improved Misclassified 85
3 Decline Misclassified 41
4 Decline Taxonomic 2
5 Improved Taxonomic 7
6 Decline Unclear 41
7 Improved Unclear 117The "5-number" summary
df.describe()
species
count 8.000000
mean 41.625000
std 40.177952
min 2.000000
25% 13.750000
50% 32.500000
75% 52.000000
max 117.000000Drop a column
df=df.drop('reason',axis=1) Result:
category species
0 Decline 24
1 Improved 16
2 Improved 85
3 Decline 41
4 Decline 2
5 Improved 7
6 Decline 41
7 Improved 117Use the collections.counter to count the frequency of words in a text.
import collections
ln='''
The electrical and thermal conductivities of metals originate from
the fact that their outer electrons are delocalized. This situation
can be visualized by seeing the atomic structure of a metal as a
collection of atoms embedded in a sea of highly mobile electrons. The
electrical conductivity, as well as the electrons' contribution to
the heat capacity and heat conductivity of metals can be calculated
from the free electron model, which does not take into account the
detailed structure of the ion lattice.
When considering the electronic band structure and binding energy of
a metal, it is necessary to take into account the positive potential
caused by the specific arrangement of the ion cores - which is
periodic in crystals. The most important consequence of the periodic
potential is the formation of a small band gap at the boundary of the
Brillouin zone. Mathematically, the potential of the ion cores can be
treated by various models, the simplest being the nearly free
electron model.'''Split the text into words:
words=ln.lower().split()Create a Counter:
ctr=collections.Counter(words)Most frequent:
ctr.most_common(10)
[('the', 22),
('of', 12),
('a', 5),
('be', 3),
('by', 3),
('ion', 3),
('can', 3),
('and', 3),
('is', 3),
('as', 3)]Alternative: via df['col'].value_counts of pandas
import re
import pandas as pd
def removePunctuation(line):
return re.sub( "\s+"," ", re.sub( "[^a-zA-Z0-9 ]", "", line)).rstrip(' ').lstrip(' ').lower()
df=pd.DataFrame( [ removePunctuation(word.lower()) for word in ln.split() ], columns=['word'])
df['word'].value_counts()Result:
the 22
of 12
a 5
and 3
by 3
as 3
ion 3
..
..Add a column of zeros to a matrix
x= np.array([ [9.,4.,7.,3.], [ 2., 0., 3., 4.], [ 1.,2.,3.,1.] ])
array([[ 9., 4., 7., 3.],
[ 2., 0., 3., 4.],
[ 1., 2., 3., 1.]])Add the column:
np.c_[ np.zeros(3), x]
array([[ 0., 9., 4., 7., 3.],
[ 0., 2., 0., 3., 4.],
[ 0., 1., 2., 3., 1.]])Watchout: np.c_ takes SQUARE brackets, not parenthesis!
There is also an np.r_[ ... ] function. Maybe also have a look at vstack and hstack. See stackoverflow.com/a/8505658/4866785 for examples.
Get the indexes that would sort an array
Using numpy's argsort.
word_arr = np.array( ['lobated', 'demured', 'fristed', 'aproned', 'sheened', 'emulged',
'bestrid', 'mourned', 'upended', 'slashed'])
idx_sorted= np.argsort(word_arr)
idx_sorted
array([3, 6, 1, 5, 2, 0, 7, 4, 9, 8])Let's look at the first and last three elements:
print "First three :", word_arr[ idx_sorted[:3] ]
First three : ['aproned' 'bestrid' 'demured']
print "Last three :", word_arr[ idx_sorted[-3:] ]
Last three : ['sheened' 'slashed' 'upended']Index of min / max element
Using numpy's argmin.
Min:
In [4]: np.argmin(word_arr)
3
print word_arr[np.argmin(word_arr)]
apronedMax:
np.argmax(word_arr)
8
print word_arr[np.argmax(word_arr)]
upendedPlot with simple legend
Use 'label' in your plot() call.
import math
import matplotlib.pyplot as plt
xv= map( lambda x: (x/4.)-10., range(0,81))
for l in [ 0.1, 0.5, 1., 5.] :
yv= map( lambda x: math.exp((-(-x)**2)/l), xv)
plt.plot(xv,yv,label='lambda = '+str(l));
plt.legend()
plt.show()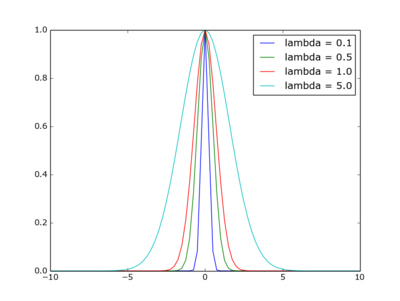
Sidenote: the function plotted is that of the Gaussian kernel in weighted nearest neighour regression, with xi=0
Startup a simple http server
python -m SimpleHTTPServerAnd yes, that's all there is to it.
Only serves HEAD and GET, uses the current directory as root.
For python 3 it goes like this:
python3 -m http.server 5000Generate n numbers in an interval
Return evenly spaced numbers over a specified interval.
Pre-req:
import numpy as np
import matplotlib.pyplot as pltIn linear space
y=np.linspace(0,90,num=10)
array([ 0., 10., 20., 30., 40., 50., 60., 70., 80., 90.])
x=[ i for i in range(len(y)) ]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
plt.plot(x,y)
plt.scatter(x,y)
plt.title("linspace")
plt.show()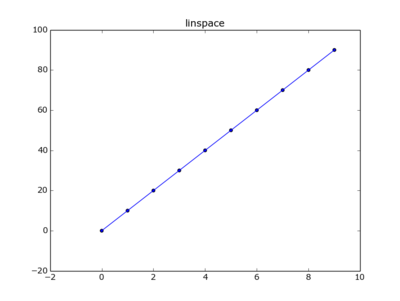
In log space
y=np.logspace(0, 9, num=10)
array([ 1.00000000e+00, 1.00000000e+01, 1.00000000e+02,
1.00000000e+03, 1.00000000e+04, 1.00000000e+05,
1.00000000e+06, 1.00000000e+07, 1.00000000e+08,
1.00000000e+09])
x=[ i for i in range(len(y)) ]
plt.plot(x,y)
plt.scatter(x,y)
plt.title("logspace")
plt.show()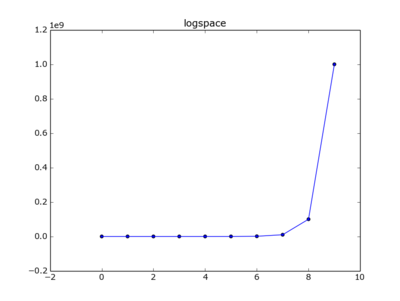
Plotting the latter on a log scale..
plt.plot(x,y)
plt.scatter(x,y)
plt.yscale('log')
plt.title("logspace on y-logscale")
plt.show()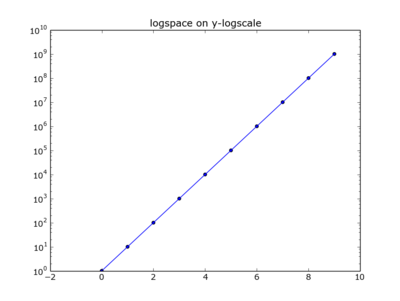
Check the indexes on k-fold split
Suppose you split a list of n words into splits of k=5, what are the indexes of the splits?
Pseudo-code:
for i in 0..5:
start = n*i/k
end = n*(i+1)/kDouble check
Double check the above index formulas with words which have the same beginletter in a split (for easy validation).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Output:
Split 0 of 5, length 7 : ['argot', 'along', 'addax', 'azans', 'aboil', 'aband', 'ayelp']
Split 1 of 5, length 7 : ['erred', 'ester', 'ekkas', 'entry', 'eldin', 'eruvs', 'ephas']
Split 2 of 5, length 7 : ['imino', 'islet', 'inurn', 'iller', 'idiom', 'izars', 'iring']
Split 3 of 5, length 7 : ['oches', 'outer', 'odist', 'orbit', 'ofays', 'outed', 'owned']
Split 4 of 5, length 7 : ['unlaw', 'upjet', 'upend', 'urged', 'urent', 'uncus', 'updry']Matrix multiplication : dot product
a= np.array([[2., -1., 0.],[-3.,6.0,1.0]])
array([[ 2., -1., 0.],
[-3., 6., 1.]])
b= np.array([ [1.0,0.0,-1.0,2],[-4.,3.,1.,0.],[0.,3.,0.,-2.]])
array([[ 1., 0., -1., 2.],
[-4., 3., 1., 0.],
[ 0., 3., 0., -2.]])
np.dot(a,b)
array([[ 6., -3., -3., 4.],
[-27., 21., 9., -8.]])Dot product of two vectors
Take the first row of above a matrix and the first column of above b matrix:
np.dot( np.array([ 2., -1., 0.]), np.array([ 1.,-4.,0. ]) )
6.0Normalize a matrix
Normalize the columns: suppose the columns make up the features, and the rows the observations.
Calculate the 'normalizers':
norms=np.linalg.norm(a,axis=0)
print norms
[ 3.60555128 6.08276253 1. ]Turn a into normalized matrix an:
an = a/norms
print an
[[ 0.5547002 -0.16439899 0. ]
[-0.83205029 0.98639392 1. ]]Produce sample words
Use the sowpods file to generate a list of words that fulfills a special condition (eg length, starting letter) Use is made of the function random.sample(population, k) to take a unique sample of a larger list.
1 2 3 4 5 6 7 8 9 10 11 12 | |
Output:
['argot', 'along', 'addax', 'azans', 'aboil', 'aband']
['erred', 'ester', 'ekkas', 'entry', 'eldin', 'eruvs']
['imino', 'islet', 'inurn', 'iller', 'idiom', 'izars']
['oches', 'outer', 'odist', 'orbit', 'ofays', 'outed']
['unlaw', 'upjet', 'upend', 'urged', 'urent', 'uncus']Cut and paste python on the command line
Simple example: number the lines in a text file
Read the file 'message.txt' and print a linenumber plus the line content.
python - message.txt <<EOF
import sys
i=1
with open(sys.argv[1],"r") as f:
for l in f.readlines():
print i,l.strip('\n')
i+=1
EOFOutput:
1 Better shutdown your ftp service.
2
3 W. Create a python program that reads a csv file, and uses the named fields
TBD.
Use namedtuple
Also see districtdatalabs.silvrback.com/simple-csv-data-wrangling-with-python
A good starting place:
matplotlib.org/mpl_toolkits/mplot3d/tutorial.html
Simple 3D scatter plot
Preliminary
from mpl_toolkits.mplot3d import axes3d
import matplotlib.pyplot as plt
import numpy as npData : create matrix X,Y,Z
X=[ [ i for i in range(0,10) ], ]*10
Y=np.transpose(X)
Z=[]
for i in range(len(X)):
R=[]
for j in range(len(Y)):
if i==j: R.append(2)
else: R.append(1)
Z.append(R)X:
[[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]]Y:
[[0, 0, 0, 0, 0],
[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4]])Z:
[[2, 1, 1, 1, 1],
[1, 2, 1, 1, 1],
[1, 1, 2, 1, 1],
[1, 1, 1, 2, 1],
[1, 1, 1, 1, 2]]Scatter plot
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X, Y, Z)
plt.show()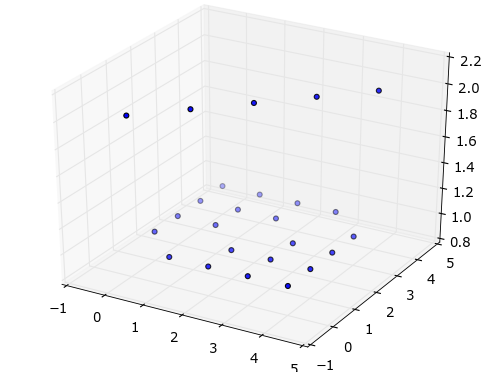
Wireframe plot
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Named Tuple
Name the fields of your tuples
- namedtuple : factory function for creating tuple subclasses with named fields
- returns a new tuple subclass named typename.
- the new subclass is used to create tuple-like objects that have fields accessible by attribute lookup as well as being indexable and iterable.
Code:
import collections
Coord = collections.namedtuple('Coord', ['x','y'], verbose=False)
a=[ Coord(100.0,20.0), Coord(5.0,10.0), Coord(99.0,66.0) ]Access tuple elements by index:
a[1][0]
5.0Access tuple elements by name:
a[1].x
5.0Set verbose=True to see the code:
Coord = collections.namedtuple('Coord', ['x','y'], verbose=True)
class Coord(tuple):
'Coord(x, y)'
__slots__ = ()
_fields = ('x', 'y')
def __new__(_cls, x, y):
'Create new instance of Coord(x, y)'
return _tuple.__new__(_cls, (x, y))
@classmethod
def _make(cls, iterable, new=tuple.__new__, len=len):
'Make a new Coord object from a sequence or iterable'
result = new(cls, iterable)
if len(result) != 2:
raise TypeError('Expected 2 arguments, got %d' % len(result))
return result
def __repr__(self):
'Return a nicely formatted representation string'
return 'Coord(x=%r, y=%r)' % self
def _asdict(self):
'Return a new OrderedDict which maps field names to their values'
return OrderedDict(zip(self._fields, self))
def _replace(_self, **kwds):
'Return a new Coord object replacing specified fields with new values'
result = _self._make(map(kwds.pop, ('x', 'y'), _self))
if kwds:
raise ValueError('Got unexpected field names: %r' % kwds.keys())
return result
def __getnewargs__(self):
'Return self as a plain tuple. Used by copy and pickle.'
return tuple(self)
__dict__ = _property(_asdict)
def __getstate__(self):
'Exclude the OrderedDict from pickling'
pass
x = _property(_itemgetter(0), doc='Alias for field number 0')
y = _property(_itemgetter(1), doc='Alias for field number 1')