The Python Book
All — By Topic
2019 2016 2015 2014
angle
argsort
beautifulsoup
binary
bisect
clean
collinear
covariance
cut_paste_cli
datafaking
dataframe
datetime
day_of_week
delta_time
df2sql
doctest
exif
floodfill
fold
format
frequency
gaussian
geocode
httpserver
is
join
legend
linalg
links
matrix
max
namedtuple
null
numpy
oo
osm
packaging
pandas
plot
point
range
regex
repeat
reverse
sample_words
shortcut
shorties
sort
stemming
strip_html
stripaccent
tools
visualization
zen
zip
3d aggregation angle archive argsort atan beautifulsoup binary bisect class clean collinear colsum comprehension count covariance csv cut_paste_cli datafaking dataframe datetime day_of_week delta_time deltatime df2sql distance doctest dotproduct dropnull exif file floodfill fold format formula frequency function garmin gaussian geocode geojson gps groupby html httpserver insert ipython is join kfold legend linalg links magic matrix max min namedtuple none null numpy onehot oo osm outer_product packaging pandas plot point quickies range read_data regex repeat reverse sample sample_data sample_words shortcut shorties sort split sqlite stack stemming string strip_html stripaccent tools track tuple visualization zen zip zipfile
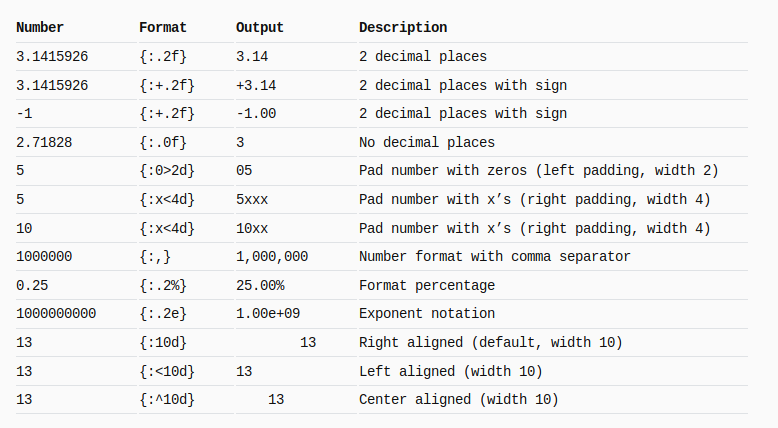
Python string format
Following snap is taken from here: mkaz.blog/code/python-string-format-cookbook. Go there, there are more examples
Convert a Garmin .FIT file and plot the heartrate of your run
Use gpsbabel to turn your FIT file into CSV:
gpsbabel -t -i garmin_fit -f 97D54119.FIT -o unicsv -F 97D54119.csvPandas imports:
import pandas as pd
import math
import matplotlib.pyplot as plt
pd.options.display.width=150Read the CSV file:
df=pd.read_csv('97D54119.csv',sep=',',skip_blank_lines=False)Show some points:
df.head(500).tail(10)
No Latitude Longitude Altitude Speed Heartrate Cadence Date Time
490 491 50.855181 4.826737 78.2 2.79 144 78.0 2019/07/13 06:44:22
491 492 50.855136 4.826739 77.6 2.79 147 78.0 2019/07/13 06:44:24
492 493 50.854962 4.826829 76.2 2.77 148 77.0 2019/07/13 06:44:32
493 494 50.854778 4.826951 77.4 2.77 146 78.0 2019/07/13 06:44:41
494 495 50.854631 4.827062 78.0 2.71 143 78.0 2019/07/13 06:44:49
495 496 50.854531 4.827174 79.2 2.70 146 77.0 2019/07/13 06:44:54
496 497 50.854472 4.827249 79.2 2.73 149 77.0 2019/07/13 06:44:57
497 498 50.854315 4.827418 79.8 2.74 149 76.0 2019/07/13 06:45:05
498 499 50.854146 4.827516 77.4 2.67 147 76.0 2019/07/13 06:45:14
499 500 50.853985 4.827430 79.0 2.59 144 75.0 2019/07/13 06:45:22Function to compute the distance (approximately) :
# function to approximately calculate the distance between 2 points
# from: http://www.movable-type.co.uk/scripts/latlong.html
def rough_distance(lat1, lon1, lat2, lon2):
lat1 = lat1 * math.pi / 180.0
lon1 = lon1 * math.pi / 180.0
lat2 = lat2 * math.pi / 180.0
lon2 = lon2 * math.pi / 180.0
r = 6371.0 #// km
x = (lon2 - lon1) * math.cos((lat1+lat2)/2)
y = (lat2 - lat1)
d = math.sqrt(x*x+y*y) * r
return dCompute the distance:
ds=[]
(d,priorlat,priorlon)=(0.0, 0.0, 0.0)
for t in df[['Latitude','Longitude']].itertuples():
if len(ds)>0:
d+=rough_distance(t.Latitude,t.Longitude, priorlat, priorlon)
ds.append(d)
(priorlat,priorlon)=(t.Latitude,t.Longitude)
df['CumulativeDist']=ds Let's plot!
df.plot(kind='line',x='CumulativeDist',y='Heartrate',color='red')
plt.show() 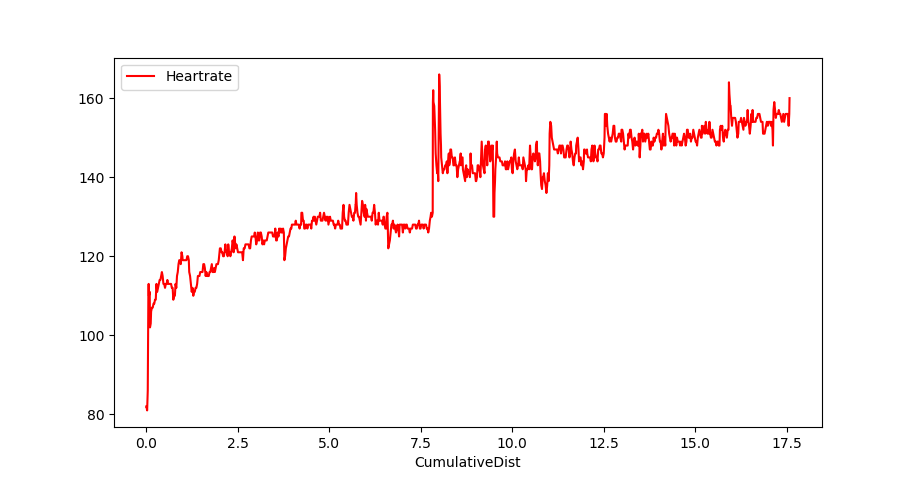
Or multiple columns:
plt.plot( df.CumulativeDist, df.Heartrate, color='red')
plt.plot( df.CumulativeDist, df.Altitude, color='blue')
plt.show()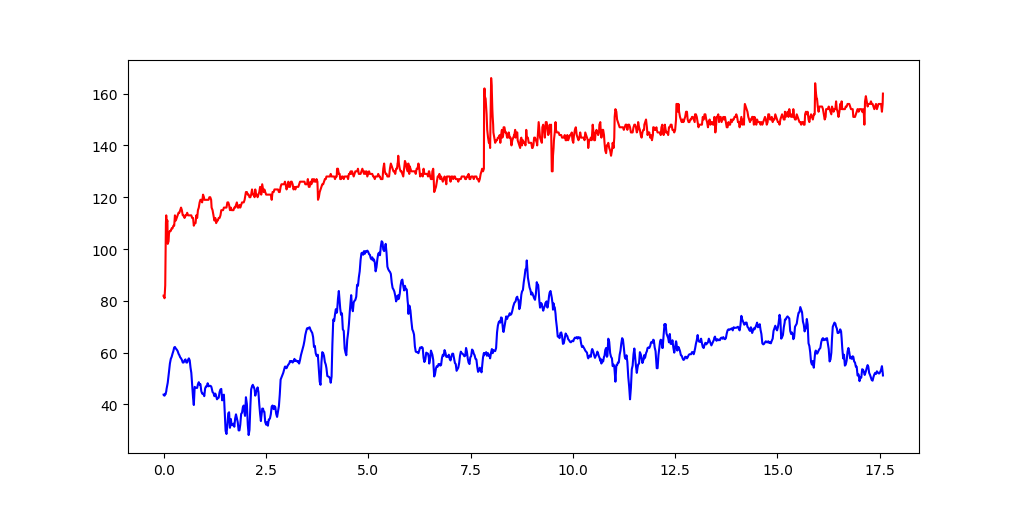
Turn a dataframe into an array
eg. dataframe cn
cn
asciiname population elevation
128677 Crossett 5507 58
7990 Santa Maria da Vitoria 23488 438
25484 Shanling 0 628
95882 Colonia Santa Teresa 36845 2286
38943 Blomberg 1498 4
7409 Missao Velha 13106 364
36937 Goerzig 1295 81Turn into an arrary
cn.iloc[range(len(cn))].values
array([['Yuhu', 0, 15],
['Traventhal', 551, 42],
['Velabisht', 0, 60],
['Almorox', 2319, 539],
['Abuyog', 15632, 6],
['Zhangshan', 0, 132],
['Llica de Vall', 0, 136],
['Capellania', 2252, 31],
['Mezocsat', 6519, 91],
['Vars', 1634, 52]], dtype=object)Sidenote: cn was pulled from city data: cn=df.sample(7)[['asciiname','population','elevation']].
Filter a dataframe to retain rows with non-null values
Eg. you want only the data where the 'population' column has non-null values.
In short
df=df[df['population'].notnull()]Alternative, replace the null value with something:
df['population']=df['population'].fillna(0) In detail
import numpy as np
import pandas as pd
# setup the dataframe
data=[[ 'Isle of Skye', 9232, 124 ],
[ 'Vieux-Charmont', np.nan, 320 ],
[ 'Indian Head', 3844, 35 ],
[ 'Cihua', np.nan, 178 ],
[ 'Miasteczko Slaskie', 7327, 301 ],
[ 'Wawa', np.nan, 7 ],
[ 'Bat Khela', 46079, 673 ]]
df=pd.DataFrame(data, columns=['asciiname','population','elevation'])
#display the dataframe
df
asciiname population elevation
0 Isle of Skye 9232.0 124
1 Vieux-Charmont NaN 320
2 Indian Head 3844.0 35
3 Cihua NaN 178
4 Miasteczko Slaskie 7327.0 301
5 Wawa NaN 7
# retain only the rows where population has a non-null value
df=df[df['population'].notnull()]
asciiname population elevation
0 Isle of Skye 9232.0 124
2 Indian Head 3844.0 35
4 Miasteczko Slaskie 7327.0 301
6 Bat Khela 46079.0 673List EXIF details of a photo
This program walks a directory, and lists selected exif data.
Install module exifread first.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
The topics of the kubercon (Kubernetes conference)
Input
Markdown doc 'source.md' with all the presentation titles plus links:
[2000 Nodes and Beyond: How We Scaled Kubernetes to 60,000-Container Clusters
and Where We're Going Next - Marek Grabowski, Google Willow
A](/event/8K8w/2000-nodes-and-beyond-how-we-scaled-kubernetes-to-60000
-container-clusters-and-where-were-going-next-marek-grabowski-google) [How Box
Runs Containers in Production with Kubernetes - Sam Ghods, Box Grand Ballroom
D](/event/8K8u/how-box-runs-containers-in-production-with-kubernetes-sam-
ghods-box) [ITNW (If This Now What) - Orchestrating an Enterprise - Michael
Ward, Pearson Grand Ballroom C](/event/8K8t/itnw-if-this-now-what-
orchestrating-an-enterprise-michael-ward-pearson) [Unik: Unikernel Runtime for
Kubernetes - Idit Levine, EMC Redwood AB](/event/8K8v/unik-unikernel-runtime-
..
..Step 1: generate download script
Grab the links from 'source.md' and download them.
#!/usr/bin/python
# -*- coding: utf-8 -*-
import re
buf=""
infile = file('source.md', 'r')
for line in infile.readlines():
buf+=line.rstrip('\n')
oo=1
while True:
match = re.search( '^(.*?\()(/.[^\)]*)(\).*$)', buf)
if match is None:
break
url="https://cnkc16.sched.org"+match.group(2)
print "wget '{}' -O {:0>4d}.html".format(url,oo)
oo+=1
buf=match.group(3)Step 2: download the html
Execute the script generated by above code, and put the resulting files in directory 'content' :
wget 'https://cnkc16.sched.org/event/8K8w/2000-nodes-and-beyond-how-
we-scaled-kubernetes-to-60000-container-clusters-and-where-were-
going-next-marek-grabowski-google' -O 0001.html
wget 'https://cnkc16.sched.org/event/8K8u/how-box-runs-containers-in-
production-with-kubernetes-sam-ghods-box' -O 0002.html
wget 'https://cnkc16.sched.org/event/8K8t/itnw-if-this-now-what-
orchestrating-an-enterprise-michael-ward-pearson' -O 0003.html
.. Step 3: parse with beautiful soup
#!/usr/bin/python
# -*- coding: utf-8 -*-
from BeautifulSoup import *
import os
import re
import codecs
#outfile = file('text.md', 'w')
# ^^^ --> UnicodeEncodeError:
# 'ascii' codec can't encode character u'\u2019'
# in position 73: ordinal not in range(128)
outfile= codecs.open("text.md", "w", "utf-8")
file_ls=[]
for filename in os.listdir("content"):
if filename.endswith(".html"):
file_ls.append(filename)
for filename in sorted(file_ls):
infile = file('content/'+filename,'r')
content = infile.read()
infile.close()
soup = BeautifulSoup(content.decode('utf-8','ignore'))
div= soup.find('div', attrs={'class':'sched-container-inner'})
el_ls= div.findAll('span')
el=el_ls[0].text.strip()
title=re.sub(' - .*$','',el)
speaker=re.sub('^.* - ','',el)
outfile.write( u'\n\n## {}\n'.format(title))
outfile.write( u'\n\n{}\n'.format(speaker) )
det= div.find('div', attrs={'class':'tip-description'})
if det is not None:
outfile.write( u'\n{}\n'.format(det.text.strip() ) )Incrementally update geocoded data
Startpoint: we have a sqlite3 database with (dirty) citynames and country codes. We would like to have the lat/lon coordinates, for each place.
Here some sample data, scraped from the Brussels marathon-results webpage, indicating the town of residence and nationality of the athlete:
LA CELLE SAINT CLOUD, FRA
TERTRE, BEL
FREDERICIA, DNK But sometimes the town and country don't match up, eg:
HEVERLEE CHN
WOLUWE-SAINT-PIERRE JPN
BUIZINGEN FRA For the geocoding we make use of nominatim.openstreetmap.org. The 3-letter country code also needs to be translated into a country name, for which we use the file /u01/data/20150215_country_code_iso/country_codes.txt.
The places for which we don't get valid (lat,lon) coordinates we put (0,0).
We run this script multiple times, small batches in the beginning, to be able see what the exceptions occur, and bigger batches in the end (when problems have been solved).
In between runs the data may be manually modified by opening the sqlite3 database, and updating/deleting the t_geocode table.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | |
A few queries
Total number of places:
select count(1) from t_geocode
916Number of places for which we didn't find valid coordinates :
select count(1) from t_geocode where lat=0 and lon=0
185Turn a pandas dataframe into a dictionary
eg. create a mapping of a 3 digit code to a country name
BEL -> Belgium
CHN -> China
FRA -> France
..Code:
df=pd.io.parsers.read_table(
'/u01/data/20150215_country_code_iso/country_codes.txt',
sep='|')
c3d=df.set_index('c3')['country'].to_dict()Result:
c3d['AUS']
'Australia'
c3d['GBR']
'United Kingdom'Create a DB by scraping a webpage
Download all the webpages and put them in a zipfile (to avoid 're-downloading' on each try).
If you want to work 'direct', then use this to read the html content of a url:
html_doc=urllib.urlopen(url).read()Preparation: create database table
cur.execute('DROP TABLE IF EXISTS t_result')
cur.execute('''
CREATE TABLE t_result(
pos varchar(128),
nr varchar(128),
gesl varchar(128),
naam varchar(128),
leeftijd varchar(128),
ioc varchar(128),
tijd varchar(128),
tkm varchar(128),
gem varchar(128),
cat_plaats varchar(128),
cat_naam varchar(128),
gemeente varchar(128)
)
''') ## Pull each html file from the zipfile
zf=zipfile.ZipFile('brx_marathon_html.zip','r')
for fn in zf.namelist():
try:
content= zf.read(fn)
handle_content(content)
except KeyError:
print 'ERROR: %s not in zip file' % fn
breakParse the content of each html file with Beautiful Soup
soup = BeautifulSoup(content)
table= soup.find('table', attrs={'cellspacing':'0', 'cellpadding':'2'})
rows = table.findAll('tr')
for row in rows:
cols = row.findAll('td')
e = [ ele.text.strip() for ele in cols]
if len(e)>10:
cur.execute('INSERT INTO T_RESULT VALUES ( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?,? )',
(e[0],e[1],e[2],e[3],e[4],e[5],e[6],e[7],e[8],e[9],e[10],e[11]) )Note: the above code is beautiful soup 3, for beautiful soup 4, the findAll needs to be replaced by find_all.
Complete source code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | |
Days between dates
Q: how many days are there in between these days ?
'29 sep 2016', '7 jul 2016', '28 apr 2016', '10 mar 2016', '14 jan 2016'Solution:
from datetime import datetime,timedelta
a=map(lambda x: datetime.strptime(x,'%d %b %Y'),
['29 sep 2016', '7 jul 2016', '28 apr 2016', '10 mar 2016', '14 jan 2016'] )
def dr(ar):
if len(ar)>1:
print "{:%d %b %Y} .. {} .. {:%d %b %Y} ".format(
ar[0], (ar[0]-ar[1]).days, ar[1])
dr(ar[1:]) Output:
dr(a)
29 Sep 2016 .. 84 .. 07 Jul 2016
07 Jul 2016 .. 70 .. 28 Apr 2016
28 Apr 2016 .. 49 .. 10 Mar 2016
10 Mar 2016 .. 56 .. 14 Jan 2016