Simple Sales Prediction
Pages:
01_intro
02_conversion
03_averages
04_difference
05_product
06_sum
07_the_omegas
08_coefficients
09_prediction
10_visualized
11_reduction
12_to_wide
99_appendix
01_intro
02_conversion
03_averages
04_difference
05_product
06_sum
07_the_omegas
08_coefficients
09_prediction
10_visualized
11_reduction
12_to_wide
99_appendix
One Page
03_averages
20160616
Calculate the averages: groupBy(..).agg(avg(..))
Let's kick off the calculations, first we do the averages of x and y:
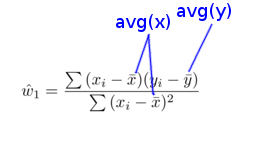
val a1 = sale_narrow_df.groupBy("shop","product").agg( avg("x"), avg("y") )Result:
a1.orderBy("shop","product").show()
+----------+-------+------------------+------------------+
| shop|product| avg(x)| avg(y)|
+----------+-------+------------------+------------------+
| megamart| bread| 6.454545454545454|461.27272727272725|
| megamart| cheese| 6.4| 56.4|
| megamart| milk| 6.7| 27.9|
| megamart| nuts| 6.5|1341.6666666666667|
| megamart| razors| 6.909090909090909| 519.5454545454545|
| megamart| soap| 7.0| 8.0|
|superstore| bread|6.2727272727272725|398.72727272727275|
|superstore| cheese| 6.9| 56.4|
|superstore| milk| 7.3| 33.5|
|superstore| nuts| 6.5|1279.1666666666667|
|superstore| razors| 6.5| 352.3333333333333|
|superstore| soap| 6.0| 7.2|
+----------+-------+------------------+------------------+Naming convention
When short name chosen for a dataframe starts with an 'a' (eg a1,a2,...) it's about an aggregate (ie at shop/product level), and when it starts with a 'd' (eg. d1,d2,..) it's about a detail (ie. at the lowest level: shop/product/month~unit)
Cosmetics
For the sake of this document: let's round off the above averages to retain just 4 digits after the decimal point, just to be able to fit more columns of data onto 1 row! When concerned with precision, please skip this step.
User defined rounding function:
def udfRound = udf[Double,Double] { (x) => Math.floor( x*10000.0 + 0.5 )/10000.0 } Round off:
val a2=a1.withColumn("avg_x", udfRound( a1("avg(x)") )).
withColumn("avg_y", udfRound( a1("avg(y)") )).
select("shop","product","avg_x","avg_y")Result:
a2.orderBy("shop","product").show()
+----------+-------+------+---------+
| shop|product| avg_x| avg_y|
+----------+-------+------+---------+
| megamart| bread|6.4545| 461.2727|
| megamart| cheese| 6.4| 56.4|
| megamart| milk| 6.7| 27.9|
| megamart| nuts| 6.5|1341.6666|
| megamart| razors| 6.909| 519.5454|
| megamart| soap| 7.0| 8.0|
|superstore| bread|6.2727| 398.7272|
|superstore| cheese| 6.9| 56.4|
|superstore| milk| 7.3| 33.5|
|superstore| nuts| 6.5|1279.1666|
|superstore| razors| 6.5| 352.3333|
|superstore| soap| 6.0| 7.2|
+----------+-------+------+---------+'Glue' these averages onto dataframe sale_narrow_df, using a left-outer join :
val d1= sale_narrow_df.join( a2, Seq("shop","product"), "leftouter")Result:
d1.orderBy("shop","product","x").show()
+--------+-------+---+---+------+--------+
| shop|product| x| y| avg_x| avg_y|
+--------+-------+---+---+------+--------+
|megamart| bread| 1|371|6.4545|461.2727|
|megamart| bread| 2|432|6.4545|461.2727|
|megamart| bread| 3|425|6.4545|461.2727|
|megamart| bread| 4|524|6.4545|461.2727|
|megamart| bread| 5|468|6.4545|461.2727|
|megamart| bread| 6|414|6.4545|461.2727|
|megamart| bread| 8|487|6.4545|461.2727|
|megamart| bread| 9|493|6.4545|461.2727|
|megamart| bread| 10|517|6.4545|461.2727|
|megamart| bread| 11|473|6.4545|461.2727|
|megamart| bread| 12|470|6.4545|461.2727|
|megamart| cheese| 1| 51| 6.4| 56.4|
|megamart| cheese| 2| 56| 6.4| 56.4|
|megamart| cheese| 3| 63| 6.4| 56.4|
..
..