| |
Intro
The intention of this article is to show how similar operations are applied to the same data on different platforms, ranging from SQL on Postgres to R and Python Pandas, and Spark Scala.
Create dataframe from arrays
Heres' how to create dataframes udf and tdf (aka tables t_user and t_transaction) from simple arrays.
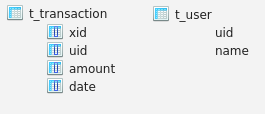
Create dataframe udf
Create a dataframe from arrays:
id_v=c(9000, 9001, 9002, 9003, 9004, 9005, 9006, 9007, 9008)
name_v=c('Gerd Abrahamsson', 'Hanna Andersson', 'August Bergsten',
'Arvid Bohlin', 'Edvard Marklund', 'Ragnhild Brännström',
'Börje Wallin', 'Otto Byström','Elise Dahlström')
udf=data.frame( uid=id_v, name=name_v)
Content of udf:
uid name
1 9000 Gerd Abrahamsson
2 9001 Hanna Andersson
3 9002 August Bergsten
4 9003 Arvid Bohlin
5 9004 Edvard Marklund
6 9005 Ragnhild Brännström
7 9006 Börje Wallin
8 9007 Otto Byström
9 9008 Elise Dahlström
Create dataframe tdf
xid_v <- c( 5000, 5001, 5002, 5003, 5004, 5005, 5006, 5007, 5008, 5009, 5010, 5011, 5012,
5013, 5014, 5015, 5016, 5017, 5018, 5019, 5020)
uid_v <- c( 9008, 9003, 9003, 9007, 9004, 9007, 9002, 9008, 9005, 9008, 9006, 9008, 9008,
9005, 9005, 9001, 9000, 9003, 9002, 9001, 9004)
amount_v <- c(498, 268, 621, -401, 720, -492, -153, 272, -250, 82, 549, -571, 814, -114,
819, -404, -95, 428, -549, -462, -339)
date_v <- c('2016-02-21 06:28:49', '2016-01-17 13:37:38', '2016-02-24 15:36:53',
'2016-01-14 16:43:27', '2016-05-14 16:29:54', '2016-02-24 23:58:57',
'2016-02-18 17:58:33', '2016-05-26 12:00:00', '2016-02-24 23:14:52',
'2016-04-20 18:33:25', '2016-02-16 14:37:25', '2016-02-28 13:05:33',
'2016-03-20 13:29:11', '2016-02-06 14:55:10', '2016-01-18 10:50:20',
'2016-02-20 22:08:23', '2016-05-09 10:26:05', '2016-03-27 15:30:47',
'2016-04-15 21:44:49', '2016-03-09 20:32:35', '2016-05-03 17:11:21')
tdf<-data.frame( xid=xid_v, uid=uid_v, amount=amount_v, date=as.POSIXct(date_v) )
Content of tdf:
xid uid amount date
1 5000 9008 498 2016-02-21 06:28:49
2 5001 9003 268 2016-01-17 13:37:38
3 5002 9003 621 2016-02-24 15:36:53
4 5003 9007 -401 2016-01-14 16:43:27
5 5004 9004 720 2016-05-14 16:29:54
6 5005 9007 -492 2016-02-24 23:58:57
7 5006 9002 -153 2016-02-18 17:58:33
8 5007 9008 272 2016-05-26 12:00:00
9 5008 9005 -250 2016-02-24 23:14:52
10 5009 9008 82 2016-04-20 18:33:25
11 5010 9006 549 2016-02-16 14:37:25
12 5011 9008 -571 2016-02-28 13:05:33
13 5012 9008 814 2016-03-20 13:29:11
14 5013 9005 -114 2016-02-06 14:55:10
15 5014 9005 819 2016-01-18 10:50:20
16 5015 9001 -404 2016-02-20 22:08:23
17 5016 9000 -95 2016-05-09 10:26:05
18 5017 9003 428 2016-03-27 15:30:47
19 5018 9002 -549 2016-04-15 21:44:49
20 5019 9001 -462 2016-03-09 20:32:35
21 5020 9004 -339 2016-05-03 17:11:21
Create dataframe udf
Create a dataframe from arrays:
import pandas as pd
uid_v= [9000, 9001, 9002, 9003, 9004, 9005, 9006, 9007, 9008]
name_v=[u'Gerd Abrahamsson', u'Hanna Andersson', u'August Bergsten',
u'Arvid Bohlin', u'Edvard Marklund', u'Ragnhild Br\xe4nnstr\xf6m',
u'B\xf6rje Wallin', u'Otto Bystr\xf6m',u'Elise Dahlstr\xf6m']
udf=pd.DataFrame(uid_v, columns=['uid'])
udf['name']=name_v
Content of udf:
uid name
0 9000 Gerd Abrahamsson
1 9001 Hanna Andersson
2 9002 August Bergsten
3 9003 Arvid Bohlin
4 9004 Edvard Marklund
5 9005 Ragnhild Brännström
6 9006 Börje Wallin
7 9007 Otto Byström
8 9008 Elise Dahlström
Create dataframe tdf
xid_v=[ 5000, 5001, 5002, 5003, 5004, 5005, 5006, 5007, 5008, 5009, 5010, 5011, 5012,
5013, 5014, 5015, 5016, 5017, 5018, 5019, 5020]
uid_v=[ 9008, 9003, 9003, 9007, 9004, 9007, 9002, 9008, 9005, 9008, 9006, 9008, 9008,
9005, 9005, 9001, 9000, 9003, 9002, 9001, 9004]
amount_v= [498, 268, 621, -401, 720, -492, -153, 272, -250, 82, 549, -571, 814, -114,
819, -404, -95, 428, -549, -462, -339]
date_v=['2016-02-21 06:28:49', '2016-01-17 13:37:38', '2016-02-24 15:36:53',
'2016-01-14 16:43:27', '2016-05-14 16:29:54', '2016-02-24 23:58:57',
'2016-02-18 17:58:33', '2016-05-26 12:00:00', '2016-02-24 23:14:52',
'2016-04-20 18:33:25', '2016-02-16 14:37:25', '2016-02-28 13:05:33',
'2016-03-20 13:29:11', '2016-02-06 14:55:10', '2016-01-18 10:50:20',
'2016-02-20 22:08:23', '2016-05-09 10:26:05', '2016-03-27 15:30:47',
'2016-04-15 21:44:49', '2016-03-09 20:32:35', '2016-05-03 17:11:21']
tdf=pd.DataFrame(xid_v, columns=['xid'])
tdf['uid']=uid_v
tdf['amount']=amount_v
tdf['date']=pd.to_datetime(date_v)
Content of tdf:
xid uid amount date
0 5000 9008 498 2016-02-21 06:28:49
1 5001 9003 268 2016-01-17 13:37:38
2 5002 9003 621 2016-02-24 15:36:53
3 5003 9007 -401 2016-01-14 16:43:27
4 5004 9004 720 2016-05-14 16:29:54
5 5005 9007 -492 2016-02-24 23:58:57
6 5006 9002 -153 2016-02-18 17:58:33
7 5007 9008 272 2016-05-26 12:00:00
8 5008 9005 -250 2016-02-24 23:14:52
9 5009 9008 82 2016-04-20 18:33:25
10 5010 9006 549 2016-02-16 14:37:25
11 5011 9008 -571 2016-02-28 13:05:33
12 5012 9008 814 2016-03-20 13:29:11
13 5013 9005 -114 2016-02-06 14:55:10
14 5014 9005 819 2016-01-18 10:50:20
15 5015 9001 -404 2016-02-20 22:08:23
16 5016 9000 -95 2016-05-09 10:26:05
17 5017 9003 428 2016-03-27 15:30:47
18 5018 9002 -549 2016-04-15 21:44:49
19 5019 9001 -462 2016-03-09 20:32:35
20 5020 9004 -339 2016-05-03 17:11:21
Example: select data from a certain date range
from datetime import datetime
startdate=datetime.strptime('2016-02-01','%Y-%m-%d')
enddate=datetime.strptime('2016-02-29','%Y-%m-%d')
tdf[((tdf.txdate >= startdate) & (tdf.txdate <=enddate))]
The easiest way to generate the sql statements is to use python pandas to connect and export the dataframes to a sqlite database, like this:
import sqlite3
con=sqlite3.connect('db.sqlite')
udf.to_sql(name='t_user', con=con, index=False)
tdf.to_sql(name='t_transaction', con=con, index=False)
con.close()
Then issue this command on the CLI :
sqlite3 db.sqlite .dump > create.sql
.. to give you these SQL statements:
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE "t_user" (
"uid" INTEGER,
"name" TEXT
);
INSERT INTO "t_user" VALUES(9000,'Gerd Abrahamsson');
INSERT INTO "t_user" VALUES(9001,'Hanna Andersson');
INSERT INTO "t_user" VALUES(9002,'August Bergsten');
INSERT INTO "t_user" VALUES(9003,'Arvid Bohlin');
INSERT INTO "t_user" VALUES(9004,'Edvard Marklund');
INSERT INTO "t_user" VALUES(9005,'Ragnhild Brännström');
INSERT INTO "t_user" VALUES(9006,'Börje Wallin');
INSERT INTO "t_user" VALUES(9007,'Otto Byström');
INSERT INTO "t_user" VALUES(9008,'Elise Dahlström');
CREATE TABLE "t_transaction" (
"xid" INTEGER,
"uid" INTEGER,
"amount" INTEGER,
"date" TIMESTAMP
);
INSERT INTO "t_transaction" VALUES(5000,9008,498,'2016-02-21 06:28:49');
INSERT INTO "t_transaction" VALUES(5001,9003,268,'2016-01-17 13:37:38');
INSERT INTO "t_transaction" VALUES(5002,9003,621,'2016-02-24 15:36:53');
INSERT INTO "t_transaction" VALUES(5003,9007,-401,'2016-01-14 16:43:27');
INSERT INTO "t_transaction" VALUES(5004,9004,720,'2016-05-14 16:29:54');
INSERT INTO "t_transaction" VALUES(5005,9007,-492,'2016-02-24 23:58:57');
INSERT INTO "t_transaction" VALUES(5006,9002,-153,'2016-02-18 17:58:33');
INSERT INTO "t_transaction" VALUES(5007,9008,272,'2016-05-26 12:00:00');
INSERT INTO "t_transaction" VALUES(5008,9005,-250,'2016-02-24 23:14:52');
INSERT INTO "t_transaction" VALUES(5009,9008,82,'2016-04-20 18:33:25');
INSERT INTO "t_transaction" VALUES(5010,9006,549,'2016-02-16 14:37:25');
INSERT INTO "t_transaction" VALUES(5011,9008,-571,'2016-02-28 13:05:33');
INSERT INTO "t_transaction" VALUES(5012,9008,814,'2016-03-20 13:29:11');
INSERT INTO "t_transaction" VALUES(5013,9005,-114,'2016-02-06 14:55:10');
INSERT INTO "t_transaction" VALUES(5014,9005,819,'2016-01-18 10:50:20');
INSERT INTO "t_transaction" VALUES(5015,9001,-404,'2016-02-20 22:08:23');
INSERT INTO "t_transaction" VALUES(5016,9000,-95,'2016-05-09 10:26:05');
INSERT INTO "t_transaction" VALUES(5017,9003,428,'2016-03-27 15:30:47');
INSERT INTO "t_transaction" VALUES(5018,9002,-549,'2016-04-15 21:44:49');
INSERT INTO "t_transaction" VALUES(5019,9001,-462,'2016-03-09 20:32:35');
INSERT INTO "t_transaction" VALUES(5020,9004,-339,'2016-05-03 17:11:21');
COMMIT;
Add these index creation statements for completeness:
CREATE INDEX "ix_t_user_uid" ON "t_user" ("uid");
CREATE INDEX "ix_t_transaction_xid" ON "t_transaction" ("xid");
This is a bit different then prior tab's: instead of creating from columns, we create it from a sequence of rows.
Run the following in the Spark shell:
val udf_df=sx.createDataFrame(Seq(
(9000,"Gerd Abrahamsson"),
(9001,"Hanna Andersson"),
(9002,"August Bergsten"),
(9003,"Arvid Bohlin"),
(9004,"Edvard Marklund"),
(9005,"Ragnhild Brännström"),
(9006,"Börje Wallin"),
(9007,"Otto Byström"),
(9008,"Elise Dahlström"))).toDF( "uid","name")
import java.sql.Timestamp
val date_format=new java.text.SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val udfToDate=udf[Timestamp,String]{ (s) =>
new java.sql.Timestamp(date_format.parse(s).getTime()) }
val tdf_df=sx.createDataFrame(Seq(
(5000,9008,498,"2016-02-21 06:28:49"),
(5001,9003,268,"2016-01-17 13:37:38"),
(5002,9003,621,"2016-02-24 15:36:53"),
(5003,9007,-401,"2016-01-14 16:43:27"),
(5004,9004,720,"2016-05-14 16:29:54"),
(5005,9007,-492,"2016-02-24 23:58:57"),
(5006,9002,-153,"2016-02-18 17:58:33"),
(5007,9008,272,"2016-05-26 12:00:00"),
(5008,9005,-250,"2016-02-24 23:14:52"),
(5009,9008,82,"2016-04-20 18:33:25"),
(5010,9006,549,"2016-02-16 14:37:25"),
(5011,9008,-571,"2016-02-28 13:05:33"),
(5012,9008,814,"2016-03-20 13:29:11"),
(5013,9005,-114,"2016-02-06 14:55:10"),
(5014,9005,819,"2016-01-18 10:50:20"),
(5015,9001,-404,"2016-02-20 22:08:23"),
(5016,9000,-95,"2016-05-09 10:26:05"),
(5017,9003,428,"2016-03-27 15:30:47"),
(5018,9002,-549,"2016-04-15 21:44:49"),
(5019,9001,-462,"2016-03-09 20:32:35"),
(5020,9004,-339,"2016-05-03 17:11:21"))
).toDF( "xid","uid","amount","date").
.withColumn("date", udfToDate($"date"))
Et voila: the dataframes udf_df and tdf_df.
..
Sidenote: create fake data
The above user and transaction data was created using the following script, which employs the fake-factory package ( 'pip install fake-factory') to generated random data
The python code:
from faker import Factory
import pandas as pd
import random
fake = Factory.create('sv_SE')
# create user data
uid_v=[]
name_v=[]
for i in range(0,9):
uid_v.append(9000+i)
name_v.append(fake.name())
# create transaction data
xid_v=[]
uid_v=[]
amount_v=[]
date_v=[]
sign=[-1,1]
for i in range(0,21):
xid_v.append(5000+i)
amount_v.append(sign[random.randint(0,1)]*random.randint(80,900))
uid_v.append(id_v[random.randint(0,len(id_v)-1)])
date_v.append(str(fake.date_time_this_year()))
Load the data from a csv file
Load data, from a CSV file containing city-names, country-code, the location (latitude, longitude), elevation and population, as provided by geonames.org: download.geonames.org/export/dump
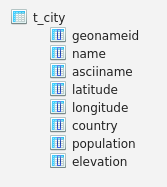
- the dataset cities1000.txt can be downloaded in a zipfile from geonames.org.
- this file contains one line for every city with a population greater than 1000. For more information see 'geoname' table stub on above link
- fields are separated by tabs
- some fields will be ignored
Startup the Spark shell, and load the data file, into an RDD[String]:
$ spark-shell
var tx=sc.textFile("file:///home/dmn/city_data/cities1000.txt")
tx.count()
Long = 145725
Define a case class, and a parse function :
case class City(
geonameid: Int,
name: String,
asciiname: String,
latitude: Double, longitude: Double,
country: String,
population: Int,
elevation: Int)
def parse(line: String) = {
val spl=line.split("\t")
val geonameid=spl(0).toInt
val name=spl(1)
val asciiname=spl(2)
val latitude=spl(4).toDouble
val longitude=spl(5).toDouble
val country=spl(8)
val population=spl(14).toInt
val elevation=spl(16).toInt
City(geonameid, name, asciiname, latitude, longitude, country, population, elevation)
}
Try and parse 1 line:
parse(tx.take(1)(0))
City = City(3039154,El Tarter,El Tarter,42.57952,1.65362,AD,1052,1721)
Success! Now let's parse the complete text file into City records:
var ct=tx.map(parse(_))
Check:
ct.count
Long = 145725
Spot-check: list all cities above 3500m and having a population of more than 100000, ordered by descending elevation:
var chk=ct.filter( rec => ( rec.elevation>3500) && (rec.population>100000)).collect()
chk.sortWith( (x,y) => (x.elevation>y.elevation) ).foreach(println)
City(3907584,Potosí,Potosi,-19.58361,-65.75306,BO,141251,3967)
City(3909234,Oruro,Oruro,-17.98333,-67.15,BO,208684,3936)
City(3937513,Juliaca,Juliaca,-15.5,-70.13333,PE,245675,3834)
City(3931276,Puno,Puno,-15.8422,-70.0199,PE,116552,3825)
City(3911925,La Paz,La Paz,-16.5,-68.15,BO,812799,3782)
City(1280737,Lhasa,Lhasa,29.65,91.1,CN,118721,3651)
Sidenote: a case class has a restricted number of parameters, if there are too many, you'll get this error:
Implementation restriction: case classes cannot have more than 22 parameters.
Startup the Spark shell, and load the data file, into an RDD[String]:
$ spark-shell
var tx=sc.textFile("file:///home/dmn/city_data/cities1000.txt")
tx.count()
Long = 145725
Import some needed types:
import org.apache.spark.sql.types.{StructType,StructField,StringType,LongType,DoubleType};
import org.apache.spark.sql.Row;
Create the SQL context:
val sqlctx= new org.apache.spark.sql.SQLContext(sc)
Define the schema:
val schema = StructType(Array(
StructField("geonameid",LongType,false),
StructField("name",StringType,true),
StructField("asciiname",StringType,true),
StructField("latitude",DoubleType,true),
StructField("longitude",DoubleType,true),
StructField("country",StringType,true),
StructField("population",LongType,true),
StructField("elevation",LongType,true)
) )
Turn the text-line RDD into a row RDD:
val rowrdd = tx.map(_.split("\t")).map(p =>
Row(p(0).toLong,p(1), p(2),
p(4).toDouble,p(5).toDouble,
p(8),p(14).toLong,p(16).toLong) )
Create the dataframe:
val city_df=sqlctx.createDataFrame(rowrdd,schema)
Spotcheck:
city_df.filter(" elevation>3500 and population>100000 ").
orderBy(desc("elevation")).
collect().
foreach(println)
[3907584,Potosí,Potosi,-19.58361,-65.75306,BO,141251,3967]
[3909234,Oruro,Oruro,-17.98333,-67.15,BO,208684,3936]
[3937513,Juliaca,Juliaca,-15.5,-70.13333,PE,245675,3834]
[3931276,Puno,Puno,-15.8422,-70.0199,PE,116552,3825]
[3911925,La Paz,La Paz,-16.5,-68.15,BO,812799,3782]
[1280737,Lhasa,Lhasa,29.65,91.1,CN,118721,3651]
For future use
Save the dataframe as a parquet file ..
city_df.write.parquet("hdfs:///user/dmn/cities/city_parquet")
.. for easy retrieval in the future:
val city_df= sqlctx.read.parquet("hdfs:///user/dmn/cities/city_parquet")
See tab Spark Dataframe, on how to create the dataframe city_df :
Then register the table:
city_df.registerTempTable("city")
And Bob's your uncle.
Spotcheck:
sqlctx.sql("select * from city where elevation>3500 and population>100000 order by elevation desc").
collect().foreach(println)
[3907584,Potosí,Potosi,-19.58361,-65.75306,BO,141251,3967]
[3909234,Oruro,Oruro,-17.98333,-67.15,BO,208684,3936]
[3937513,Juliaca,Juliaca,-15.5,-70.13333,PE,245675,3834]
[3931276,Puno,Puno,-15.8422,-70.0199,PE,116552,3825]
[3911925,La Paz,La Paz,-16.5,-68.15,BO,812799,3782]
[1280737,Lhasa,Lhasa,29.65,91.1,CN,118721,3651]
Note: if you run above without the collect() then the ordering may be incorrect.
R:
df<-read.table("/home/dmn/city_data/cities1000.txt",sep="\t"
,quote="",stringsAsFactors=F, na.strings = "",
)[,c(1, 2, 3, 5, 6, 9, 15, 17)]
names(df)<-c("geonameid","name","asciiname","latitude","longitude",
"country","population","elevation")
options(width=200)
Note: if you don't set na.strings = "" in this case, then all Namibia (code 'NA') records are flagged as having NA for country. Check: table(is.na(df$country)) should give all F's and no T's.
Dimensions:
dim(df)
145725 8
Spotcheck: cities above 3500m and having a population of more than 100000:
tf=df[(df$elevation>3500)&(df$population>100000),]
tf[order(-tf$elevation),]
geonameid name asciiname latitude longitude country population elevation
7015 3907584 Potosí Potosi -19.58361 -65.75306 BO 141251 3967
7026 3909234 Oruro Oruro -17.98333 -67.15000 BO 208684 3936
101370 3937513 Juliaca Juliaca -15.50000 -70.13333 PE 245675 3834
101162 3931276 Puno Puno -15.84220 -70.01990 PE 116552 3825
7044 3911925 La Paz La Paz -16.50000 -68.15000 BO 812799 3782
12297 1280737 Lhasa Lhasa 29.65000 91.10000 CN 118721 3651
Read tab-separated file into a data.table
Read:
library(data.table)
dt<-fread("/home/dmn/city_data/cities1000.txt", header=FALSE,
na.strings = "",
select=c(1, 2, 3, 5, 6, 9, 15, 17) )
setnames(dt,c("geonameid","name","asciiname","latitude","longitude",
"country","population","elevation"))
options(width=200)
Spotcheck: cities above 3500m and having a population of more than 100000:
dt[(dt$elevation>3500)&(dt$population>100000),][order(-elevation),]
geonameid name asciiname latitude longitude country population elevation
1: 3907584 Potosí Potosi -19.58361 -65.75306 BO 141251 3967
2: 3909234 Oruro Oruro -17.98333 -67.15000 BO 208684 3936
3: 3937513 Juliaca Juliaca -15.50000 -70.13333 PE 245675 3834
4: 3931276 Puno Puno -15.84220 -70.01990 PE 116552 3825
5: 3911925 La Paz La Paz -16.50000 -68.15000 BO 812799 3782
6: 1280737 Lhasa Lhasa 29.65000 91.10000 CN 118721 3651
See also: http://pandas.pydata.org/pandas-docs/stable/io.html :
import pandas as pd
import csv
colnames= [ "geonameid","name","asciiname","latitude","longitude",
"country","population","elevation" ]
df=pd.io.parsers.read_table("/home/dmn/city_data/cities1000.txt",
sep="\t", header=None, names= colnames,
quoting=csv.QUOTE_NONE,usecols=[ 0, 1, 2, 4, 5, 8, 14, 16])
pd.set_option('display.width', 200)
Number of records:
len(df)
145725
Spotcheck: cities above 3500m and having a population of more than 100000:
df[(df.elevation>3500) & (df.population>100000)].sort("elevation",ascending=False)
geonameid name asciiname latitude longitude country population elevation
7014 3907584 Potosí Potosi -19.58361 -65.75306 BO 141251 3967
7025 3909234 Oruro Oruro -17.98333 -67.15000 BO 208684 3936
100330 3937513 Juliaca Juliaca -15.50000 -70.13333 PE 245675 3834
100122 3931276 Puno Puno -15.84220 -70.01990 PE 116552 3825
7043 3911925 La Paz La Paz -16.50000 -68.15000 BO 812799 3782
12296 1280737 Lhasa Lhasa 29.65000 91.10000 CN 118721 3651
Preprocessing
The data will be loaded into a Postgres table using the copy command. With this command, it's not possible to only load a subset of columns, therefore we are using R to preprocess the file.
Startup R, read selected columns of the input, then copy the data out into file "cities.csv" :
df<-read.table("/home/dmn/city_data/cities1000.txt", sep="\t",
quote="",stringsAsFactors=F)[,c(1, 2, 3, 5, 6, 9, 15, 17)]
# corrections for city names with a double quote in their name:
df[df$V1==1682560,c("V2","V3")]=c("T-boli","T-boli")
df[df$V1==688022,c("V2","V3")]=c("Yur-yivka","Yur-yivka")
write.table(df,"cities.csv", sep="\t",row.names=F,col.names=F,na="",quote=F)
Sidenote: create a postgres database user
On the linux CLI :
sudo -u postgres psql template1
template1=# create user dmn encrypted password 'dmn';
template1=# create DATABASE dmn WITH TEMPLATE = template0 ENCODING = 'UTF8' owner dmn;
template1=# \q
Startup psql :
psql -h localhost -U dmn
Load into postgres
Startup psql, and create the table:
create table t_city (
geonameid int primary key
,name varchar(128)
,asciiname varchar(128)
,latitude numeric
,longitude numeric
,country varchar(5)
,population int
,elevation int
);
Load the data:
\copy t_city from 'cities.csv' with DELIMITER E'\t' CSV
Count:
select count(1) from t_city
count
--------
145725
Spotcheck: cities above 3500m and having a population of more than 100000:
select *
from t_city
where elevation>3500 and population>100000
order by elevation desc;
geonameid | name | asciiname | latitude | longitude | country | population | elevation
-----------+---------+-----------+-----------+-----------+---------+------------+-----------
3907584 | Potosí | Potosi | -19.58361 | -65.75306 | BO | 141251 | 3967
3909234 | Oruro | Oruro | -17.98333 | -67.15 | BO | 208684 | 3936
3937513 | Juliaca | Juliaca | -15.5 | -70.13333 | PE | 245675 | 3834
3931276 | Puno | Puno | -15.8422 | -70.0199 | PE | 116552 | 3825
3911925 | La Paz | La Paz | -16.5 | -68.15 | BO | 812799 | 3782
1280737 | Lhasa | Lhasa | 29.65 | 91.1 | CN | 118721 | 3651
That concludes the loading!
Aggregate
Simple aggregate: sum the population of the cities for the EU28 countries.
Data entity used: city (see section 2b data load ).
Scala spark
Prep:
val eu28=List("AT", "BE", "BG", "CY", "CZ", "DE", "DK", "EE", "ES", "FI", "FR",
"GB", "GR", "HR", "HU", "IE", "IT", "LT", "LU", "LV", "MT", "NL",
"PL", "PT", "RO", "SE", "SI", "SK", "AN")
Query:
ct.filter( r => (eu28 contains r.country)). // retain cities of the 28 EU countries
map( r => (r.country, r.population)). // create (country, population) tuples
reduceByKey( (_ + _)). // sum up
sortBy(-_._2). // sort by value, negative sign for desc
foreach( println)
(DE,85880759)
(GB,63628475)
(FR,52643435)
(IT,52376411)
(ES,49756525)
(PL,28776423)
(RO,25000006)
(NL,15022475)
(HU,10263483)
(BE,10117760)
(CZ,8720141)
(GR,8562837)
(SE,7803509)
(PT,7097218)
(BG,5457463)
(FI,5178753)
(AT,4924993)
(DK,4475046)
(HR,3744956)
(IE,3548735)
(SK,2971938)
(LT,2755868)
(LV,1735119)
(SI,1183740)
(EE,995124)
(CY,797327)
(MT,398419)
(LU,358224)
Query:
sqlctx.sql("""select country, sum(population) as sum_pop
from city
where country in ('AT','BE','BG','CY','CZ','DE','DK','EE','ES','FI','FR',
'GB','GR','HR','HU','IE','IT','LT','LU','LV','MT','NL',
'PL','PT','RO','SE','SI','SK','AN')
group by country
order by sum_pop desc""").collect().foreach(println)
Result:
[DE,85880759]
[GB,63628475]
[FR,52643435]
[IT,52376411]
[ES,49756525]
[PL,28776423]
[RO,25000006]
[NL,15022475]
[HU,10263483]
[BE,10117760]
[CZ,8720141]
[GR,8562837]
[SE,7803509]
[PT,7097218]
[BG,5457463]
[FI,5178753]
[AT,4924993]
[DK,4475046]
[HR,3744956]
[IE,3548735]
[SK,2971938]
[LT,2755868]
[LV,1735119]
[SI,1183740]
[EE,995124]
[CY,797327]
[MT,398419]
[LU,358224]
The list of countries that make-up the EU28 :
eu28=c("AT", "BE", "BG", "CY", "CZ", "DE", "DK", "EE", "ES", "FI", "FR",
"GB", "GR", "HR", "HU", "IE", "IT", "LT", "LU", "LV", "MT", "NL",
"PL", "PT", "RO", "SE", "SI", "SK", "AN")
Create a subset:
eudf=df[df$country %in% eu28,]
dim(eudf)
57251 8
Aggregate:
aggregate( eudf$population, by=list(country=eudf$country),sum)
country x
1 AT 4924993
2 BE 10117760
3 BG 5457463
4 CY 797327
5 CZ 8720141
6 DE 85880759
7 DK 4475046
8 EE 995124
9 ES 49756525
10 FI 5178753
11 FR 52643435
12 GB 63628475
13 GR 8562837
14 HR 3744956
15 HU 10263483
16 IE 3548735
17 IT 52376411
18 LT 2755868
19 LU 358224
20 LV 1735119
21 MT 398419
22 NL 15022475
23 PL 28776423
24 PT 7097218
25 RO 25000006
26 SE 7803509
27 SI 1183740
28 SK 2971938
Prep:
eu28=c("AT", "BE", "BG", "CY", "CZ", "DE", "DK", "EE", "ES", "FI", "FR",
"GB", "GR", "HR", "HU", "IE", "IT", "LT", "LU", "LV", "MT", "NL",
"PL", "PT", "RO", "SE", "SI", "SK", "AN")
For data.tables both operations (subsetting and aggregation) can be written as a one-liner:
dt[country %in% eu28][,sum(population),by=country]
country V1
1: AT 4924993
2: BE 10117760
3: BG 5457463
4: CY 797327
5: CZ 8720141
6: DE 85880759
7: DK 4475046
8: EE 995124
9: ES 49756525
10: FI 5178753
11: FR 52643435
12: GB 63628475
13: GR 8562837
14: HR 3744956
15: HU 10263483
16: IE 3548735
17: IT 52376411
18: LT 2755868
19: LU 358224
20: LV 1735119
21: MT 398419
22: NL 15022475
23: PL 28776423
24: PT 7097218
25: RO 25000006
26: SE 7803509
27: SI 1183740
28: SK 2971938
Python
Prep:
eu28=set(["AT", "BE", "BG", "CY", "CZ", "DE", "DK", "EE", "ES", "FI", "FR",
"GB", "GR", "HR", "HU", "IE", "IT", "LT", "LU", "LV", "MT", "NL",
"PL", "PT", "RO", "SE", "SI", "SK", "AN"])
Agg:
df[df.country.isin(eu28)][["country","population"]].groupby(['country']).sum()
country population
AT 4924993
BE 10117760
BG 5457463
CY 797327
CZ 8720141
DE 85880759
DK 4475046
EE 995124
ES 49756525
FI 5178753
FR 52643435
GB 50690526
GR 8562837
HR 3744956
HU 10263483
IE 3548735
IT 52376411
LT 2755868
LU 358224
LV 1735119
MT 398419
NL 15022475
PL 28776423
PT 7097218
RO 25000006
SE 7803509
SI 1183740
SK 2971938
Postgres:
select country, sum(population) as sum_pop
from t_city
where country in ('AT', 'BE', 'BG', 'CY', 'CZ', 'DE', 'DK', 'EE', 'ES', 'FI', 'FR',
'GB', 'GR', 'HR', 'HU', 'IE', 'IT', 'LT', 'LU', 'LV', 'MT', 'NL',
'PL', 'PT', 'RO', 'SE', 'SI', 'SK', 'AN')
group by country
order by 2 desc;
Result:
country | sum_pop
---------+----------
DE | 85880759
GB | 63628475
FR | 52643435
IT | 52376411
ES | 49756525
PL | 28776423
RO | 25000006
NL | 15022475
HU | 10263483
BE | 10117760
CZ | 8720141
GR | 8562837
SE | 7803509
PT | 7097218
BG | 5457463
FI | 5178753
AT | 4924993
DK | 4475046
HR | 3744956
IE | 3548735
SK | 2971938
LT | 2755868
LV | 1735119
SI | 1183740
EE | 995124
CY | 797327
MT | 398419
LU | 358224
(28 rows)
Frequency
Count the occurrence of the city names, and list the top 20. Additional condition: population has to be greater than 100.
Data entity used: city (see section 2b data load ).
Query:
ct.filter( r => r.population>100).
map( r => (r.asciiname, 1) ).
reduceByKey( (_ + _)).
sortBy(-_._2).
take(20).
foreach(println)
Result:
(San Antonio,31)
(San Miguel,31)
(San Francisco,28)
(San Jose,26)
(San Isidro,25)
(Santa Cruz,25)
(Buenavista,24)
(Clinton,24)
(Newport,24)
(San Vicente,23)
(Victoria,23)
(Santa Maria,23)
(Richmond,22)
(San Carlos,21)
(Santa Ana,21)
(Georgetown,21)
(San Pedro,20)
(Springfield,20)
(Franklin,20)
(Salem,19)
Another way is to use the RDD.countByValue function which for RDD[T] returns Map[T,Long]. BUT this turns our RDD into a scala.collection.Map[String,Long], ie. it's now a 'local' collection, and no longer distributed.
ct.filter( r => r.population>100).
map( r => r.asciiname ).
countByValue().
toList.
sortBy(-_._2).
take(20).foreach(println)
Query:
city_df.filter(" population>100 ").
groupBy("asciiname").count().
orderBy(desc("count")).
take(20).
foreach(println)
Result:
[San Miguel,31]
[San Antonio,31]
[San Francisco,28]
[San Jose,26]
[San Isidro,25]
[Santa Cruz,25]
[Clinton,24]
[Buenavista,24]
[Newport,24]
[Victoria,23]
[Santa Maria,23]
[San Vicente,23]
[Richmond,22]
[Santa Ana,21]
[San Carlos,21]
[Georgetown,21]
[Springfield,20]
[Franklin,20]
[San Pedro,20]
[Greenville,19]
Query:
sqlctx.sql("""
select asciiname, count(1) as cnt
from city
where population>100
group by asciiname
order by cnt desc
limit 20
""").collect().foreach(println)
Result:
[San Antonio,31]
[San Miguel,31]
[San Francisco,28]
[San Jose,26]
[San Isidro,25]
[Santa Cruz,25]
[Clinton,24]
[Buenavista,24]
[Newport,24]
[Santa Maria,23]
[Victoria,23]
[San Vicente,23]
[Richmond,22]
[San Carlos,21]
[Georgetown,21]
[Santa Ana,21]
[Franklin,20]
[Springfield,20]
[San Pedro,20]
[La Union,19]
Making use of the count function of plyr:
library(plyr)
ff=count(df[df$population>100,], "asciiname")
ff[order(-ff$freq)[1:20],]
asciiname freq
75375 San Antonio 31
76514 San Miguel 31
75784 San Francisco 28
76042 San Jose 26
76000 San Isidro 25
77019 Santa Cruz 25
12900 Buenavista 24
19349 Clinton 24
59090 Newport 24
77184 Santa Maria 23
77720 San Vicente 23
92062 Victoria 23
71507 Richmond 22
30887 Georgetown 21
75521 San Carlos 21
76926 Santa Ana 21
29256 Franklin 20
76679 San Pedro 20
82832 Springfield 20
32755 Greenville 19
dt[population>100][,.N,by=asciiname][order(-N)][1:20]
asciiname N
1: San Miguel 31
2: San Antonio 31
3: San Francisco 28
4: San Jose 26
5: San Isidro 25
6: Santa Cruz 25
7: Newport 24
8: Buenavista 24
9: Clinton 24
10: San Vicente 23
11: Santa Maria 23
12: Victoria 23
13: Richmond 22
14: Santa Ana 21
15: San Carlos 21
16: Georgetown 21
17: San Pedro 20
18: Franklin 20
19: Springfield 20
20: Windsor 19
Applying value_counts() to a dataframe column returns a series.
df[df.population>100]["asciiname"].value_counts()[:20]
San Antonio 31
San Miguel 31
San Francisco 28
San Jose 26
Santa Cruz 25
San Isidro 25
Newport 24
Clinton 24
Buenavista 24
Santa Maria 23
San Vicente 23
Victoria 23
Richmond 22
San Carlos 21
Santa Ana 21
Georgetown 21
San Pedro 20
Franklin 20
Springfield 20
Greenville 19
Another way is to use the collections.Counter:
import collections
ctr=collections.Counter( df[df.population>100]["asciiname"])
ctr.most_common(20)
[('San Miguel', 31),
('San Antonio', 31),
('San Francisco', 28),
('San Jose', 26),
('Santa Cruz', 25),
('San Isidro', 25),
('Buenavista', 24),
('Newport', 24),
('Clinton', 24),
('Santa Maria', 23),
('San Vicente', 23),
('Victoria', 23),
('Richmond', 22),
('San Carlos', 21),
('Santa Ana', 21),
('Georgetown', 21),
('San Pedro', 20),
('Franklin', 20),
('Springfield', 20),
('Salem', 19)]
postgres
select asciiname,count(1)
from t_city
where population>100
group by asciiname
order by 2 desc
limit 20
asciiname | count
---------------+-------
San Antonio | 31
San Miguel | 31
San Francisco | 28
San Jose | 26
San Isidro | 25
Santa Cruz | 25
Buenavista | 24
Clinton | 24
Newport | 24
San Vicente | 23
Santa Maria | 23
Victoria | 23
Richmond | 22
Santa Ana | 21
Georgetown | 21
San Carlos | 21
Franklin | 20
Springfield | 20
San Pedro | 20
Greenville | 19
(20 rows)
Join data sql style
Data entities used: user and transaction (see section 2a data create ).
merge()
merge(udf,tdf, by.x="id", by.y="uid")
id name xid amount date
1 9000 Gerd Abrahamsson 5016 -95 2016-05-09 10:26:05
2 9001 Hanna Andersson 5015 -404 2016-02-20 22:08:23
3 9001 Hanna Andersson 5019 -462 2016-03-09 20:32:35
4 9002 August Bergsten 5006 -153 2016-02-18 17:58:33
5 9002 August Bergsten 5018 -549 2016-04-15 21:44:49
6 9003 Arvid Bohlin 5001 268 2016-01-17 13:37:38
7 9003 Arvid Bohlin 5017 428 2016-03-27 15:30:47
8 9003 Arvid Bohlin 5002 621 2016-02-24 15:36:53
9 9004 Edvard Marklund 5004 720 2016-05-14 16:29:54
10 9004 Edvard Marklund 5020 -339 2016-05-03 17:11:21
11 9005 Ragnhild Brännström 5013 -114 2016-02-06 14:55:10
12 9005 Ragnhild Brännström 5008 -250 2016-02-24 23:14:52
13 9005 Ragnhild Brännström 5014 819 2016-01-18 10:50:20
14 9006 Börje Wallin 5010 549 2016-02-16 14:37:25
15 9007 Otto Byström 5003 -401 2016-01-14 16:43:27
16 9007 Otto Byström 5005 -492 2016-02-24 23:58:57
17 9008 Elise Dahlström 5007 272 2016-05-26 12:00:00
18 9008 Elise Dahlström 5000 498 2016-02-21 06:28:49
19 9008 Elise Dahlström 5009 82 2016-04-20 18:33:25
20 9008 Elise Dahlström 5011 -571 2016-02-28 13:05:33
21 9008 Elise Dahlström 5012 814 2016-03-20 13:29:11
pd.merge()
pd.merge( tdf, udf, how='inner', left_on='uid', right_on='uid')
xid uid amount date name
0 5000 9008 498 2016-02-21 06:28:49 Elise Dahlström
1 5007 9008 272 2016-05-26 12:00:00 Elise Dahlström
2 5009 9008 82 2016-04-20 18:33:25 Elise Dahlström
3 5011 9008 -571 2016-02-28 13:05:33 Elise Dahlström
4 5012 9008 814 2016-03-20 13:29:11 Elise Dahlström
5 5001 9003 268 2016-01-17 13:37:38 Arvid Bohlin
6 5002 9003 621 2016-02-24 15:36:53 Arvid Bohlin
7 5017 9003 428 2016-03-27 15:30:47 Arvid Bohlin
8 5003 9007 -401 2016-01-14 16:43:27 Otto Byström
9 5005 9007 -492 2016-02-24 23:58:57 Otto Byström
10 5004 9004 720 2016-05-14 16:29:54 Edvard Marklund
11 5020 9004 -339 2016-05-03 17:11:21 Edvard Marklund
12 5006 9002 -153 2016-02-18 17:58:33 August Bergsten
13 5018 9002 -549 2016-04-15 21:44:49 August Bergsten
14 5008 9005 -250 2016-02-24 23:14:52 Ragnhild Brännström
15 5013 9005 -114 2016-02-06 14:55:10 Ragnhild Brännström
16 5014 9005 819 2016-01-18 10:50:20 Ragnhild Brännström
17 5010 9006 549 2016-02-16 14:37:25 Börje Wallin
18 5015 9001 -404 2016-02-20 22:08:23 Hanna Andersson
19 5019 9001 -462 2016-03-09 20:32:35 Hanna Andersson
20 5016 9000 -95 2016-05-09 10:26:05 Gerd Abrahamsson
Join
dmn=> select t.xid, t.amount, t.date, t.uid, u.name
from t_transaction t join t_user u
on t.uid=u.uid;
xid | amount | date | uid | name
------+--------+---------------------+------+---------------------
5000 | 498 | 2016-02-21 06:28:49 | 9008 | Elise Dahlström
5001 | 268 | 2016-01-17 13:37:38 | 9003 | Arvid Bohlin
5002 | 621 | 2016-02-24 15:36:53 | 9003 | Arvid Bohlin
5003 | -401 | 2016-01-14 16:43:27 | 9007 | Otto Byström
5004 | 720 | 2016-05-14 16:29:54 | 9004 | Edvard Marklund
5005 | -492 | 2016-02-24 23:58:57 | 9007 | Otto Byström
5006 | -153 | 2016-02-18 17:58:33 | 9002 | August Bergsten
5007 | 272 | 2016-05-26 12:00:00 | 9008 | Elise Dahlström
5008 | -250 | 2016-02-24 23:14:52 | 9005 | Ragnhild Brännström
5009 | 82 | 2016-04-20 18:33:25 | 9008 | Elise Dahlström
5010 | 549 | 2016-02-16 14:37:25 | 9006 | Börje Wallin
5011 | -571 | 2016-02-28 13:05:33 | 9008 | Elise Dahlström
5012 | 814 | 2016-03-20 13:29:11 | 9008 | Elise Dahlström
5013 | -114 | 2016-02-06 14:55:10 | 9005 | Ragnhild Brännström
5014 | 819 | 2016-01-18 10:50:20 | 9005 | Ragnhild Brännström
5015 | -404 | 2016-02-20 22:08:23 | 9001 | Hanna Andersson
5016 | -95 | 2016-05-09 10:26:05 | 9000 | Gerd Abrahamsson
5017 | 428 | 2016-03-27 15:30:47 | 9003 | Arvid Bohlin
5018 | -549 | 2016-04-15 21:44:49 | 9002 | August Bergsten
5019 | -462 | 2016-03-09 20:32:35 | 9001 | Hanna Andersson
5020 | -339 | 2016-05-03 17:11:21 | 9004 | Edvard Marklund
Join : RDD.cartesian().filter()
(see section 2a on how to create the RDDs: udf_rdd and tdf_rdd)
Create the Cartesian product of the two RDD's, and then filter out the records with corresponding id's:
val jn_rdd=udf_rdd.cartesian(tdf_rdd).filter( r => r._1.uid==r._2.uid )
This creates an RDD of this type:
jn_rdd: org.apache.spark.rdd.RDD[(Udf, Tdf)]
Result
jn_rdd.collect().foreach(println)
(Udf(9002,August Bergsten),Tdf(5006,9002,-153.0,2016-02-18 17:58:33.0))
(Udf(9003,Arvid Bohlin),Tdf(5001,9003,268.0,2016-01-17 13:37:38.0))
(Udf(9003,Arvid Bohlin),Tdf(5002,9003,621.0,2016-02-24 15:36:53.0))
(Udf(9004,Edvard Marklund),Tdf(5004,9004,720.0,2016-05-14 16:29:54.0))
(Udf(9000,Gerd Abrahamsson),Tdf(5016,9000,-95.0,2016-05-09 10:26:05.0))
(Udf(9001,Hanna Andersson),Tdf(5015,9001,-404.0,2016-02-20 22:08:23.0))
(Udf(9001,Hanna Andersson),Tdf(5019,9001,-462.0,2016-03-09 20:32:35.0))
(Udf(9002,August Bergsten),Tdf(5018,9002,-549.0,2016-04-15 21:44:49.0))
(Udf(9003,Arvid Bohlin),Tdf(5017,9003,428.0,2016-03-27 15:30:47.0))
(Udf(9004,Edvard Marklund),Tdf(5020,9004,-339.0,2016-05-03 17:11:21.0))
(Udf(9005,Ragnhild Brännström),Tdf(5008,9005,-250.0,2016-02-24 23:14:52.0))
(Udf(9006,Börje Wallin),Tdf(5010,9006,549.0,2016-02-16 14:37:25.0))
(Udf(9007,Otto Byström),Tdf(5003,9007,-401.0,2016-01-14 16:43:27.0))
(Udf(9007,Otto Byström),Tdf(5005,9007,-492.0,2016-02-24 23:58:57.0))
(Udf(9008,Elise Dahlström),Tdf(5000,9008,498.0,2016-02-21 06:28:49.0))
(Udf(9008,Elise Dahlström),Tdf(5007,9008,272.0,2016-05-26 12:00:00.0))
(Udf(9008,Elise Dahlström),Tdf(5009,9008,82.0,2016-04-20 18:33:25.0))
(Udf(9005,Ragnhild Brännström),Tdf(5013,9005,-114.0,2016-02-06 14:55:10.0))
(Udf(9005,Ragnhild Brännström),Tdf(5014,9005,819.0,2016-01-18 10:50:20.0))
(Udf(9008,Elise Dahlström),Tdf(5011,9008,-571.0,2016-02-28 13:05:33.0))
(Udf(9008,Elise Dahlström),Tdf(5012,9008,814.0,2016-03-20 13:29:11.0))
Dataframe.join()
val jn_df=udf_df.join( tdf_df, udf_df("uid")===tdf_df("uid") )
Type:
org.apache.spark.sql.DataFrame =
[uid: int, name: string, xid: int, uid: int, amount: double, date: timestamp]
Note the duplicate uid column!
Content of the dataframe:
jn_df.collect().foreach(println)
[9000,Gerd Abrahamsson,5016,9000,-95.0,2016-05-09 10:26:05.0]
[9001,Hanna Andersson,5015,9001,-404.0,2016-02-20 22:08:23.0]
[9001,Hanna Andersson,5019,9001,-462.0,2016-03-09 20:32:35.0]
[9002,August Bergsten,5006,9002,-153.0,2016-02-18 17:58:33.0]
[9002,August Bergsten,5018,9002,-549.0,2016-04-15 21:44:49.0]
[9003,Arvid Bohlin,5001,9003,268.0,2016-01-17 13:37:38.0]
[9003,Arvid Bohlin,5002,9003,621.0,2016-02-24 15:36:53.0]
[9003,Arvid Bohlin,5017,9003,428.0,2016-03-27 15:30:47.0]
[9004,Edvard Marklund,5004,9004,720.0,2016-05-14 16:29:54.0]
[9004,Edvard Marklund,5020,9004,-339.0,2016-05-03 17:11:21.0]
[9005,Ragnhild Brännström,5008,9005,-250.0,2016-02-24 23:14:52.0]
[9005,Ragnhild Brännström,5013,9005,-114.0,2016-02-06 14:55:10.0]
[9005,Ragnhild Brännström,5014,9005,819.0,2016-01-18 10:50:20.0]
[9006,Börje Wallin,5010,9006,549.0,2016-02-16 14:37:25.0]
[9007,Otto Byström,5003,9007,-401.0,2016-01-14 16:43:27.0]
[9007,Otto Byström,5005,9007,-492.0,2016-02-24 23:58:57.0]
[9008,Elise Dahlström,5000,9008,498.0,2016-02-21 06:28:49.0]
[9008,Elise Dahlström,5007,9008,272.0,2016-05-26 12:00:00.0]
[9008,Elise Dahlström,5009,9008,82.0,2016-04-20 18:33:25.0]
[9008,Elise Dahlström,5011,9008,-571.0,2016-02-28 13:05:33.0]
[9008,Elise Dahlström,5012,9008,814.0,2016-03-20 13:29:11.0]
Join
Very similar to plain SQL:
val rs= sx.sql("""
select t.xid, t.amount, t.date, t.uid, u.name
from t_tdf t join t_udf u
on t.uid=u.uid
""")
Type:
org.apache.spark.sql.DataFrame =
[xid: int, amount: double, date: timestamp, uid: int, name: string]
Content:
rs.collect().foreach(println)
[5016,-95.0,2016-05-09 10:26:05.0,9000,Gerd Abrahamsson]
[5015,-404.0,2016-02-20 22:08:23.0,9001,Hanna Andersson]
[5019,-462.0,2016-03-09 20:32:35.0,9001,Hanna Andersson]
[5006,-153.0,2016-02-18 17:58:33.0,9002,August Bergsten]
[5018,-549.0,2016-04-15 21:44:49.0,9002,August Bergsten]
[5001,268.0,2016-01-17 13:37:38.0,9003,Arvid Bohlin]
[5002,621.0,2016-02-24 15:36:53.0,9003,Arvid Bohlin]
[5017,428.0,2016-03-27 15:30:47.0,9003,Arvid Bohlin]
[5004,720.0,2016-05-14 16:29:54.0,9004,Edvard Marklund]
[5020,-339.0,2016-05-03 17:11:21.0,9004,Edvard Marklund]
[5008,-250.0,2016-02-24 23:14:52.0,9005,Ragnhild Brännström]
[5013,-114.0,2016-02-06 14:55:10.0,9005,Ragnhild Brännström]
[5014,819.0,2016-01-18 10:50:20.0,9005,Ragnhild Brännström]
[5010,549.0,2016-02-16 14:37:25.0,9006,Börje Wallin]
[5003,-401.0,2016-01-14 16:43:27.0,9007,Otto Byström]
[5005,-492.0,2016-02-24 23:58:57.0,9007,Otto Byström]
[5000,498.0,2016-02-21 06:28:49.0,9008,Elise Dahlström]
[5007,272.0,2016-05-26 12:00:00.0,9008,Elise Dahlström]
[5009,82.0,2016-04-20 18:33:25.0,9008,Elise Dahlström]
[5011,-571.0,2016-02-28 13:05:33.0,9008,Elise Dahlström]
[5012,814.0,2016-03-20 13:29:11.0,9008,Elise Dahlström]
..
Aggregate with date range
Join the user entities and transaction entities, and sum up the transaction amounts per user for February. Order the output by amount.
# merge
jdf=merge(udf,tdf, by.x="uid", by.y="uid")
# range of dates
startdate<-as.POSIXct("2016-02-01")
enddate<-as.POSIXct("2016-02-29")
# subset
sb<-jdf[jdf$date>=startdate & jdf$date<=enddate,c('name','amount')]
# aggregate
ag<-aggregate(sb$amount, by=list(group=sb$name),sum)
ag[order(ag$x),]
Result:
group x
6 Otto Byström -492
5 Hanna Andersson -404
7 Ragnhild Brännström -364
2 August Bergsten -153
4 Elise Dahlström -73
3 Börje Wallin 549
1 Arvid Bohlin 621
from datetime import datetime
# join
jdf=pd.merge( tdf, udf, how='inner', left_on='uid', right_on='uid')
# date range
startdate=datetime.strptime('2016-02-01','%Y-%m-%d')
enddate=datetime.strptime('2016-02-29','%Y-%m-%d')
# aggregate
ag=jdf[((jdf.date >= startdate) & (jdf.date <=enddate))][[ 'name','amount']].groupby('name').sum()
# sort by amount
ag.sort_values(by='amount')
Result:
name amount
Otto Byström -492
Hanna Andersson -404
Ragnhild Brännström -364
August Bergsten -153
Elise Dahlström -73
Börje Wallin 549
Arvid Bohlin 621
Query:
select u.name,sum(t.amount) as sum
from t_transaction t join t_user u on t.uid=u.uid
where t.date between '2016-02-01' and '2016-02-29'
group by u.name
order by sum;
Result:
name | sum
---------------------+------
Otto Byström | -492
Hanna Andersson | -404
Ragnhild Brännström | -364
August Bergsten | -153
Elise Dahlström | -73
Börje Wallin | 549
Arvid Bohlin | 621
(7 rows)
Join:
val jn_rdd=udf_rdd.cartesian(tdf_rdd).filter( r => r._1.uid==r._2.uid )
Date-range:
val fmt=new java.text.SimpleDateFormat("yyyy-MM-dd")
val t1=new java.sql.Timestamp( fmt.parse("2016-02-01").getTime())
val t2=new java.sql.Timestamp( fmt.parse("2016-02-29").getTime())
Aggregate:
jn_rdd.filter( r=> ( r._2.date.after(t1) && r._2.date.before(t2)) ).
map( r => ( r._1.name, r._2.amount) ).
reduceByKey( (_+_) ).
sortBy( _._2 ).collect().foreach(println)
Result:
(Otto Byström,-492.0)
(Hanna Andersson,-404.0)
(Ragnhild Brännström,-364.0)
(August Bergsten,-153.0)
(Elise Dahlström,-73.0)
(Börje Wallin,549.0)
(Arvid Bohlin,621.0)
Top-2 ranking elements within a group
Problem
Suppose you have weekly data, classified by a key (eg. payload=sales and key=store)
week | key | payload
------+-----+---------
5 | A | 71.02
5 | B | 70.93
5 | B | 71.16
5 | E | 71.77
6 | B | 69.66
6 | F | 68.67
7 | B | 72.45
7 | C | 69.91
7 | D | 68.22
7 | F | 63.73
7 | G | 71.7
8 | B | 69.86
8 | C | 64.04
8 | E | 72
9 | A | 70.33
10 | A | 71.7
10 | C | 66.41
10 | E | 62.96
11 | A | 71.11
11 | C | 70.02
11 | E | 69.3
11 | F | 70.97
12 | D | 68.81
12 | F | 66
You want the last and penultimate payload value for every key, like this:
key | last | penultimate
-----+-------+-------------
A | 71.11 | 71.7
B | 69.86 | 72.45
C | 70.02 | 66.41
D | 68.81 | 68.22
E | 69.3 | 62.96
F | 66 | 70.97
Note:
- not every 'week' has an entry for every 'key'
- key G is missing from the final result, because it only has 1 entry
Solution
Database used: Postgres.
Table creation
create table t_weekly ( week int, key varchar(3), payload numeric);
insert into t_weekly(week,key,payload) values(5,'A',71.02);
insert into t_weekly(week,key,payload) values(5,'B',70.93);
insert into t_weekly(week,key,payload) values(5,'B',71.16);
insert into t_weekly(week,key,payload) values(5,'E',71.77);
insert into t_weekly(week,key,payload) values(6,'B',69.66);
insert into t_weekly(week,key,payload) values(6,'F',68.67);
insert into t_weekly(week,key,payload) values(7,'B',72.45);
insert into t_weekly(week,key,payload) values(7,'C',69.91);
insert into t_weekly(week,key,payload) values(7,'D',68.22);
insert into t_weekly(week,key,payload) values(7,'F',63.73);
insert into t_weekly(week,key,payload) values(7,'G',71.7);
insert into t_weekly(week,key,payload) values(8,'B',69.86);
insert into t_weekly(week,key,payload) values(8,'C',64.04);
insert into t_weekly(week,key,payload) values(8,'E',72);
insert into t_weekly(week,key,payload) values(9,'A',70.33);
insert into t_weekly(week,key,payload) values(10,'A',71.7);
insert into t_weekly(week,key,payload) values(10,'C',66.41);
insert into t_weekly(week,key,payload) values(10,'E',62.96);
insert into t_weekly(week,key,payload) values(11,'A',71.11);
insert into t_weekly(week,key,payload) values(11,'C',70.02);
insert into t_weekly(week,key,payload) values(11,'E',69.3);
insert into t_weekly(week,key,payload) values(11,'F',70.97);
insert into t_weekly(week,key,payload) values(12,'D',68.81);
insert into t_weekly(week,key,payload) values(12,'F',66);
Solution
Using the 'rank() over' functionality :
with ranked as (
select week,key,payload,rank() over (partition by key order by week desc)
from t_weekly
) select r1.key,
r1.payload as last,
r2.payload as penultim
from ranked r1 join ranked r2 on r1.key=r2.key
where r1.rank=1
and r2.rank=2
order by key
Result
key | last | penultim
-----+-------+----------
A | 71.11 | 71.7
B | 69.86 | 72.45
C | 70.02 | 66.41
D | 68.81 | 68.22
E | 69.3 | 62.96
F | 66 | 70.97
Dataframe creation
val week_df=sx.createDataFrame(Seq(
(5,"A",71.02), (5,"B",70.93), (5,"B",71.16), (5,"E",71.77), (6,"B",69.66),
(6,"F",68.67), (7,"B",72.45), (7,"C",69.91), (7,"D",68.22), (7,"F",63.73),
(7,"G",71.7), (8,"B",69.86), (8,"C",64.04), (8,"E",72.0), (9,"A",70.33),
(10,"A",71.7), (10,"C",66.41), (10,"E",62.96), (11,"A",71.11), (11,"C",70.02),
(11,"E",69.3), (11,"F",70.97), (12,"D",68.81), (12,"F",66.0))
).toDF( "week","key","payload")
Attempt 1: HiveContext needed for window functions?
Experimenting with Window.partitionBy("key").orderBy("week") threw up this error:
Could not resolve window function 'rank'. Note that, using window functions currently
requires a HiveContext;
Hmm, we don't want to be dependent on Hive. Let's try and solve it a different way.
Attempt 2
Get the top ranking values:
val toprank=week_df.groupBy("key").agg( last("week") ).
withColumnRenamed("last(week)()","toprank")
Now filter out these records from the original dataframe, and then do the 'toprank' again to get the 'secondrank':
val week_excltop_df=week_df.join(toprank,Seq("key"),"leftouter").filter("week!=toprank")
Get the second-ranking values:
val secondrank=week_excltop_df.groupBy("key").agg( last("week") ).
withColumnRenamed("last(week)()","secondrank")
Turn the ranks into values:
val s1=week_df.join( toprank,Seq("key"),"leftouter").
where("week=toprank").
select("key","payload").
withColumnRenamed("payload","final")
val s2=week_df.join( secondrank,Seq("key"),"leftouter").
where("week=secondrank").
select("key","payload").
withColumnRenamed("payload","penultim")
And join s1 and s2 together, to get the final result:
s1.join(s2, Seq("key"),"inner").show()
+---+-----+--------+
|key|final|penultim|
+---+-----+--------+
| A|71.11| 71.7|
| B|69.86| 72.45|
| C|70.02| 66.41|
| D|68.81| 68.22|
| E| 69.3| 62.96|
| F| 66.0| 70.97|
+---+-----+--------+
Dataframe creation
df= pd.DataFrame( [ { "week":5, "key":"A", "payload":71.02},
{ "week":5, "key":"B", "payload":70.93}, { "week":5, "key":"B", "payload":71.16},
{ "week":5, "key":"E", "payload":71.77}, { "week":6, "key":"B", "payload":69.66},
{ "week":6, "key":"F", "payload":68.67}, { "week":7, "key":"B", "payload":72.45},
{ "week":7, "key":"C", "payload":69.91}, { "week":7, "key":"D", "payload":68.22},
{ "week":7, "key":"F", "payload":63.73}, { "week":7, "key":"G", "payload":71.7},
{ "week":8, "key":"B", "payload":69.86}, { "week":8, "key":"C", "payload":64.04},
{ "week":8, "key":"E", "payload":72}, { "week":9, "key":"A", "payload":70.33},
{ "week":10, "key":"A", "payload":71.7}, { "week":10, "key":"C", "payload":66.41},
{ "week":10, "key":"E", "payload":62.96}, { "week":11, "key":"A", "payload":71.11},
{ "week":11, "key":"C", "payload":70.02}, { "week":11, "key":"E", "payload":69.3},
{ "week":11, "key":"F", "payload":70.97}, { "week":12, "key":"D", "payload":68.81},
{ "week":12, "key":"F", "payload":66} ] )
Result
Put the rank column into the dataframe:
gb=df.groupby( ['key'])
df['rank']=gb['week'].rank(method='min',ascending=False)
Intermediate result:
key payload week rank
0 A 71.02 5 4.0
1 B 70.93 5 4.0
2 B 71.16 5 4.0
3 E 71.77 5 4.0
4 B 69.66 6 3.0
5 F 68.67 6 4.0
6 B 72.45 7 2.0
7 C 69.91 7 4.0
8 D 68.22 7 2.0
9 F 63.73 7 3.0
10 G 71.70 7 1.0
11 B 69.86 8 1.0
12 C 64.04 8 3.0
13 E 72.00 8 3.0
14 A 70.33 9 3.0
15 A 71.70 10 2.0
Toprank:
s1=df[df['rank']==1][['key','payload']]
s1.index=s1['key']
s1.columns=['key','last']
Second rank:
s2=df[df['rank']==2][['key','payload']]
s2.index=s2['key']
s2.drop('key',axis=1,inplace=True) # to avoid it appearing twice in final result
s2.columns=['penultimate']
Join to get the final result:
rs=pd.concat( [s1,s2], axis=1, join='inner')
rs.sort_values(by='key')
Final result:
key last penultimate
key
A A 71.11 71.70
B B 69.86 72.45
C C 70.02 66.41
D D 68.81 68.22
E E 69.30 62.96
F F 66.00 70.97
The way shown here is using the dplyr package.
Dataframe creation
df<-read.table(text= gsub( '@','\n', paste0(
"'week','key','payload'@5,'A',71.02@5,'B',70.93@5,'B',71.16@5,'E',71.77@6,'B',69.66@",
"6,'F',68.67@7,'B',72.45@7,'C',69.91@7,'D',68.22@7,'F',63.73@7,'G',71.7@8,'B',69.86@",
"8,'C',64.04@8,'E',72@9,'A',70.33@10,'A',71.7@10,'C',66.41@10,'E',62.96@11,'A',71.11@",
"11,'C',70.02@11,'E',69.3@11,'F',70.97@12,'D',68.81@12,'F',66@")),sep=",",header=T)
Solution
library(dplyr)
dfr=df %>% group_by(key) %>% mutate(rank = min_rank(week))
s1=dfr[ dfr$rank==1,]
s2=dfr[ dfr$rank==2,]
res=merge (s1,s2, by.x='key',by.y='key')[,c('key','payload.x','payload.y')]
names(res)=c('key','last','penultimate')
Result:
key last penultimate
1 A 71.02 70.33
2 C 69.91 64.04
3 D 68.22 68.81
4 E 71.77 72.00
5 F 68.67 63.73
OUTTAKE
This was first filed under '02a create data', when I was convinced that it was not possible to create spark objects from columns of values: it is possible to create them from rows of values..
This section is just kept for 'historical reference'...
Create dataframe from arrays
Heres' how to create dataframes udf and tdf from CSV FILES (and not from an array like shown in section 2a)
Unfortunately there is no way to create Spark data objects (rdd's, dataframe's) from arrays. (it is possible to create Spark objects from sequences of rows!)
The easiest is to load them from CSV files. So load the arrays into python, as shown on the python-tab, and then save them to file like this:
udf.to_csv('udf.csv',header=False, index=False,encoding='utf-8')
tdf.to_csv('tdf.csv',header=False, index=False,encoding='utf-8')
Then start up the Spark-shell and run this code to load the RDD's:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.log4j.Logger
import java.time.LocalDate
import java.time.format.DateTimeFormatter
case class Udf( uid:Int, name:String)
case class Tdf( xid:Int, uid:Int, amount:Double, date:java.sql.Timestamp)
val dtfmt0= new java.text.SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
def parse_udf(line:String) = {
val _field=line.split(',')
val uid = if (_field(0).isEmpty) 0 else _field(0).toInt
val name = if (_field(1).isEmpty) "" else _field(1)
Udf ( uid, name)
}
def parse_tdf(line:String) = {
val _field=line.split(',')
val xid = if (_field(0).isEmpty) 0 else _field(0).toInt
val uid = if (_field(1).isEmpty) 0 else _field(1).toInt
val amount = if (_field(2).isEmpty) 0.0 else _field(2).toDouble
val date = if (_field(3).isEmpty) new java.sql.Timestamp(0l) else new java.sql.Timestamp(dtfmt0.parse(_field(3)).getTime())
Tdf ( xid, uid, amount, date)
}
// udf ---------------------------------------------
val udf_rdd=sc.textFile("file:///home/dmn/20160613_framed_data/udf.csv").
map(parse_udf(_))
// tdf ---------------------------------------------
val tdf_rdd=sc.textFile("file:///home/dmn/20160613_framed_data/tdf.csv").
map(parse_tdf(_))
Same remark as for Spark RDD: unfortunately there is no way to create Spark data objects from arrays. (it is possible to create Spark objects from sequences of rows!). The easiest is to load them from CSV files. So load the arrays into python, as shown on the python-tab, and then save them to file like this:
udf.to_csv('udf.csv',header=False, index=False,encoding='utf-8')
tdf.to_csv('tdf.csv',header=False, index=False,encoding='utf-8')
Run the following in the Spark shell:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.log4j.Logger
import java.time.LocalDate
import java.time.format.DateTimeFormatter
import org.apache.spark.sql.Row
import org.apache.spark.sql._
import org.apache.spark.sql.types._
val udf_schema = StructType(
StructField("uid",IntegerType,false) ::
StructField("name",StringType,false) :: Nil
)
val tdf_schema = StructType(
StructField("xid",IntegerType,false) ::
StructField("uid",IntegerType,false) ::
StructField("amount",DoubleType,false) ::
StructField("date",TimestampType,false) :: Nil
)
val dtfmt0= new java.text.SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
def parse_udf(line:String) = {
val _field=line.split(',')
val uid = if (_field(0).isEmpty) 0 else _field(0).toInt
val name = if (_field(1).isEmpty) "" else _field(1)
Row ( uid, name)
}
def parse_tdf(line:String) = {
val _field=line.split(',')
val xid = if (_field(0).isEmpty) 0 else _field(0).toInt
val uid = if (_field(1).isEmpty) 0 else _field(1).toInt
val amount = if (_field(2).isEmpty) 0.0 else _field(2).toDouble
val date = if (_field(3).isEmpty) new java.sql.Timestamp(0l)
else new java.sql.Timestamp(dtfmt0.parse(_field(3)).getTime())
Row ( xid, uid, amount, date)
}
val sx= new org.apache.spark.sql.SQLContext(sc)
// udf ---------------------------------------------
val in_udf_rdd=sc.textFile("file:///home/dmn/20160613_framed_data/udf.csv").
map(parse_udf(_))
val udf_df = sx.createDataFrame(in_udf_rdd, udf_schema)
udf_df.registerTempTable("t_udf")
// tdf ---------------------------------------------
val in_tdf_rdd=sc.textFile("file:///home/dmn/20160613_framed_data/tdf.csv").
map(parse_tdf(_))
val tdf_df = sx.createDataFrame(in_tdf_rdd, tdf_schema)
tdf_df.registerTempTable("t_tdf")
Et voila: the dataframes udf_df and tdf_df and the relational tables t_udf and t_tdf.
..
Sidenote: create fake data
The above user and transaction data was created using the following script, which employs the fake-factory package ( 'pip install fake-factory') to generated random data
The python code:
from faker import Factory
import pandas as pd
import random
fake = Factory.create('sv_SE')
# create user data
uid_v=[]
name_v=[]
for i in range(0,9):
uid_v.append(9000+i)
name_v.append(fake.name())
# create transaction data
xid_v=[]
uid_v=[]
amount_v=[]
date_v=[]
sign=[-1,1]
for i in range(0,21):
xid_v.append(5000+i)
amount_v.append(sign[random.randint(0,1)]*random.randint(80,900))
uid_v.append(id_v[random.randint(0,len(id_v)-1)])
date_v.append(str(fake.date_time_this_year()))
Shorties
Environment options
Options for the environment.
- list all options:
pd.describe_option()
- set display width:
pd.set_option('display.width', 200)
- set max column width:
pd.set_option('display.max_colwidth', 100) (default=50)
- run a script within IPython's namespace:
%run -i yourscript.py
Load a script in the spark-shell
Within spark shell:
:load yourcode.scala
On the CLI:
spark-shell -i yourcode.scala
or:
cat yourcode.scala | spark-shell
History
:history
| |