Terentia Flores
One Page
Architecture
A light-weight client written in the Go language reads the Openstreetmap protobuf file, and pumps only the waypoints into a Redis database. This can happen on a system on which there is no Hadoop nor Java installed.
Another process (a Java program) reads the data from Redis and places it on HDFS.
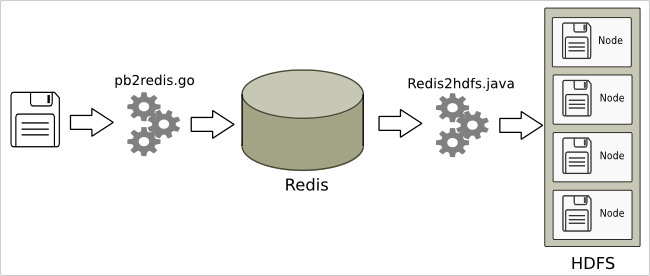
Once the data on HDFS, we are ready to fire off some SQL queries on our Hive instance!

When dealing with waypoints, we'd like to know the approximate distance between two waypoints, and for that purpose we write a custom Java function:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
It's very easy to incorporate functions such as above in Hive (see further).
Why the Redis middle-man?
If you look at the above diagrams you may ask: why don't you skip the scenic tour via the Redis database, and transfer the data directly from protobuf file to HDFS?
The main reason is that the big protobuf-file (Europe OSM PB-file is 17G) resides on a slow system with a big disk and no Hadoop installation.
Other reasons are:
- the PB-file is read by a Go-language program, for which a neat, lightweight protobuf-reading library exists. Since it is 'go', the executable has a small footprint and there is no need to install 169 jar files to have it running.
- Redis is an in-memory database, is blazing fast, and supports hash-sets and queues (and a bunch of other types)
- in the proposed setup, Redis acts as a buffer, and it is easy to detect the slower of the two processes: the ingest (the go-process pumping into Redis) or the exude (the Java process pumping out). With that knowledge we can try and increase up the performance of the slow leg (eg. make it multi-threaded).
- the intention is to re-use the code developed in this article in the future, whereby the data source system may range from a tiny Raspberry Pi, mid-range laptop up to big rack servers with the fastest SAS disks.