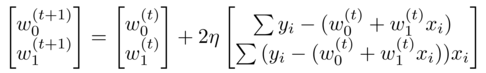Simple Linear Regression
01_intro
02_formulas
03_data
04_implementation
05_gradient_descent
99_formulas
99_nitty_gritty
One Page
Gradient descent
Minimize the Residual Sum of Squares
The slope & intercept can also be found via minimizing the RSS, which is a function of the slope (w₁) and intercept (w₀):
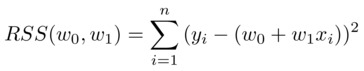
Finding the minimum or maximum corresponds to setting the derived function equal to zero.
KLAD For a concave or convex function there is only one point where there is a maximum or minimum, ie where the derivative equals zero. If a function is not concave nor convex, then it may have multiple maxima or minima.
Side-step: hill descent
The gradient descent algorithm tries to find a minimum, in a step-wise fashion. This can easily be compared to the following hill descent for a simple parabole function, eg. y = 5 + (x-10)².
Hill descent with overshoot
Suppose you start at point x=1. To see if the function is going down or up we add a minute quantity, dx, and know that we are descending if f(x) > fx(x+dx).
Increment x with step=15.0, and look again at the direction in which the function is going. Here the direction has flipped, we have overshot our target, so for the next step we need to divide the step-size into half. Etc.
Keep doing this until the difference is smaller than a predefined constant.
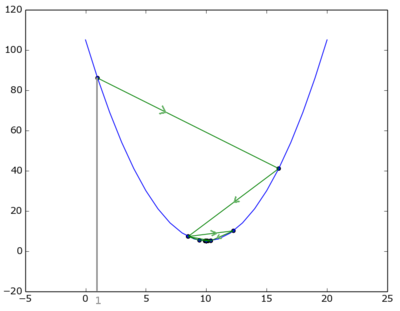
To reach the result of 9.99999773021 required 57 iterations.
12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
Hill descent without overshooting
The following algo is similar, but avoids overshooting: in case we overshoot, it keeps adjusting the step-size until we land on the left side of the minimum.
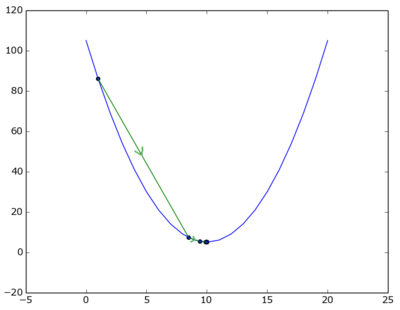
This time to get the result of 9.99999773022 required only 21 iterations, quite a bit better than above, but that of course may be due to the function and the choosen stepsize.
12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
The common functions for above code
Function and direction
5 6 7 8 9 10 | |
Plotting
5 6 7 8 9 10 | |
Mathematical approach
The above 2 solutions are the naive implementations, that perform fairly well. The mathematical way would be to calculate the next x as:
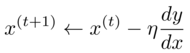
with step η typically chosen as 0.1.
During the ensuing iterations η can be kept constant or decreasing eg.
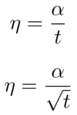
Choosing the stepsize is an art!
Gradient descent
Similarly to above, for gradient descent we update the coefficients by moving in the negative gradient direction (gradient is direction of increase). The increment in gradient descent is: